多公司多类型文件关键信息提取-v0.8.0
前面我们通过文件关键信息提取功能,可以从图片、PDF 中提取出想要的关键信息。
这对于合同、权证、发货单、签收单等各种单据的识别很有用。
但这涉及到一个前提,就是需要我们把同一类的文件先整理好放在一个文件夹下。
当我们遇到多家公司,每个公司又有很多不同类型资料需要提取的时候,就有点困难了。
为解决这个问题,我们可以先使用“文件自动分类”功能,把每个公司中同一类的文件归集到一个文件夹下。
例如:文件目录如下所示:
├── A公司
│ ├── 01、客户信用调查表
│ │ └── 必要材料调查报告.pdf
│ ├── 02、营业执照
│ │ ├── 2-必要材料营业执照.png
│ │ └── 营业执照.png
│ ├── 03、户口簿
│ │ └── 户口簿.pdf
│ ├── 调查报告
│ │ └── 必要资料调查报告.docx
│ └── 购销合同
│ └── 合同.docx
└── B公司
├── 01、客户信用调查表
│ └── 必要材料调查报告.pdf
├── 02、营业执照
│ ├── 2-必要材料营业执照.png
│ └── 营业执照.png
└── 03、户口簿
└── 户口簿.pdf然后,再使用今天介绍的功能,完成多类型文件关键信息的批量提取。
下面介绍使用方法:
AI API 设置
你可以注册一个 AI 平台的账号,将其 base_url 和 API_key 参数填写到审计工具箱的“参数设置”界面并保存。
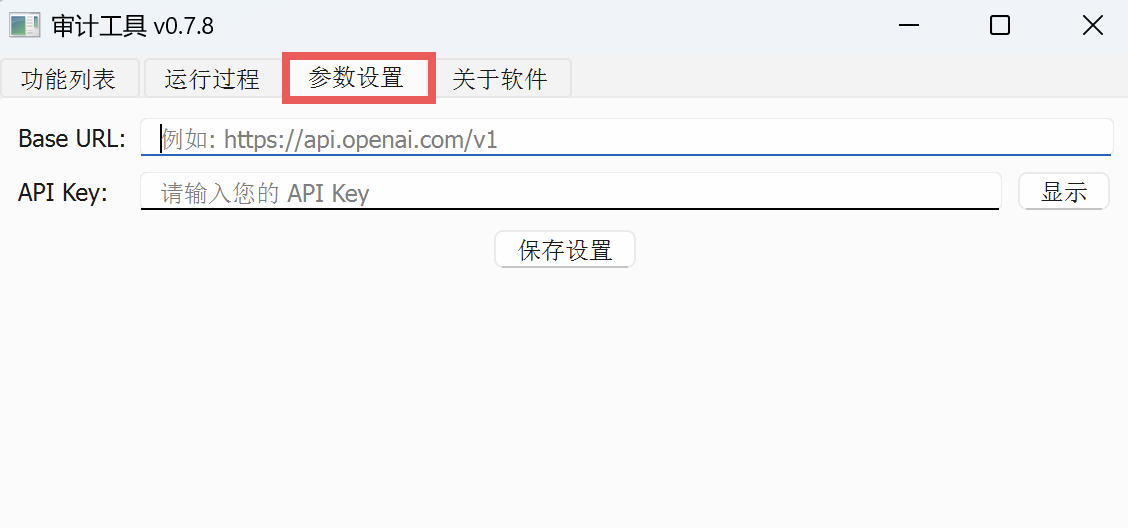
可以参考文章:《合同、权证、纳税申报表批量识别!审计工具箱v0.6.8更新》
当然,你有私有化部署 AI 的能力,也可以填写你本地或服务器部署的API 。( 兼容 openai 格式 )
如果,你注册的阿里云百炼的 API ,base_url 为: https://dashscope.aliyuncs.com/compatible-mode/v1
每个 AI 平台不同。
使用“多公司文件关键信息提取”功能
双击“多公司文件关键信息提取”,进入该功能:
点击“填写数据”,会打开配置表。
配置表填写
基础配置表填写

| 字段 | 释义 |
|---|---|
| 视觉模型名称 | 用来处理图片、扫描版本PDF的大模型。可以不动。 |
| 语言模型名称 | 用来处理文本的大模型。可以不动。 |
| 处理文件夹 | 填写上面A公司、B公司、C公司所在的文件夹。 |
| 系统提示词 | 不用动。 |
文件夹配置填写
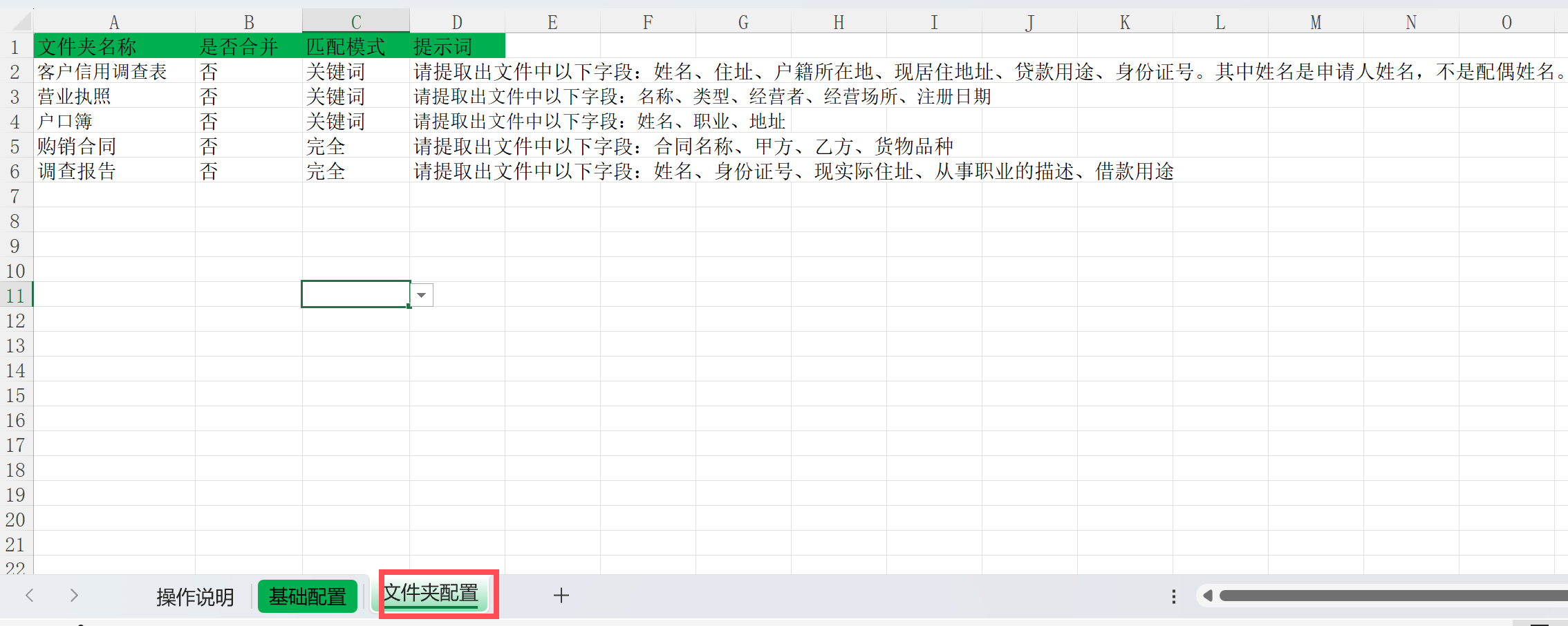
程序会在每个公司文件夹下找这个文件夹名称,可以名称完全相同或者包含关系。
=是否合并=的意思是,是否将该文件夹下所有文件当成一个文件一起发送给AI,填“否”就会每个文件单独请求,填“是”就会合并请求。 如果单独请求产生多个数据,输出时会保留不同的值。
=提示词=,你可以针对这类文件描述你希望提取的字段,有些有歧义的字段,你可以补充相关信息,使AI能准确理解。 =匹配模式=,填“完全”,则会去查找文件夹名称完全一致的进行处理。如果填“关键词”则对包含该名称的文件夹进行处理。
填写好配置表后,保存。
点击“开始运行”:
最终执行完成后,输出的文件表头样式为:

输出的样式,是根据你配置表中填写的文件类型以及对应的字段,自动生成的。
每一家公司一行数据,相关的单据字段横向排列。
工具下载
UC 网盘:
链接:https://drive.uc.cn/s/a2c2e929a9bb4 提取码:RbCJ
或者在【审计军火库网盘】中下载,路径为:
【审计军火库-02-工具模板区-审计效率工具-逆行的狗-审计工具箱】
如果测试有问题,可以在免费的【审计军火库】知识星球中反馈。