招标信息自动整理工作流(二)
上篇文章,我们已经获取了公告详情页信息,并将附件文件下载了下来。
下面,我们就需要根据详情页和附件文件提取出结构化信息。
详情页结构化信息提取
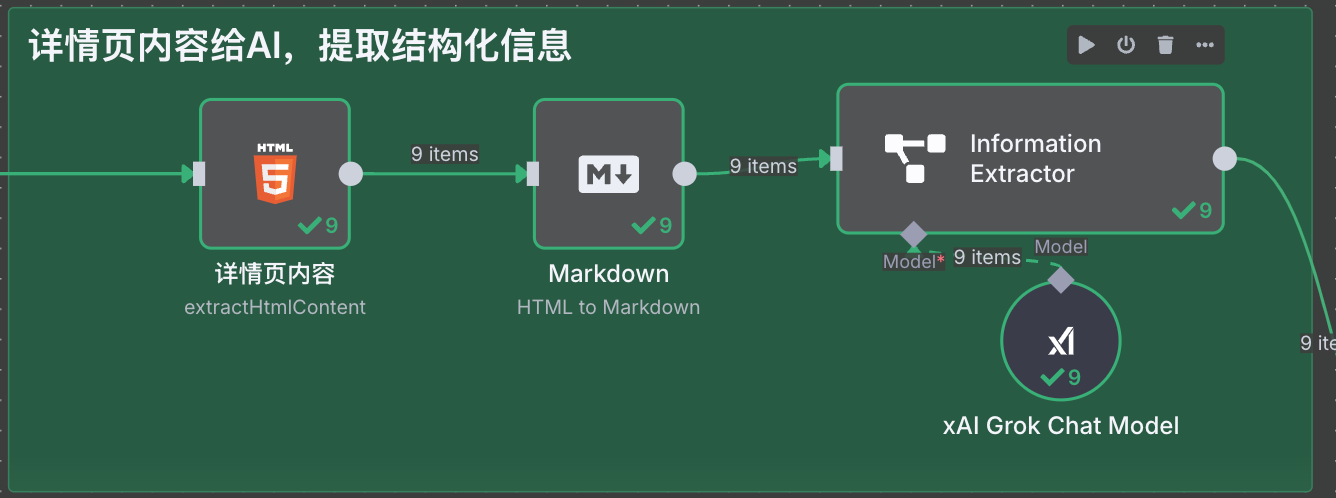
我们将详情页 http 请求返回的文本,通过 html 节点用 selector `#content` 提取正文的html标签,
再用 markdown 节点转换成文本。
接着再用 n8n 自带的 `information Extractor` AI agent 节点,挂一个大语言模型。
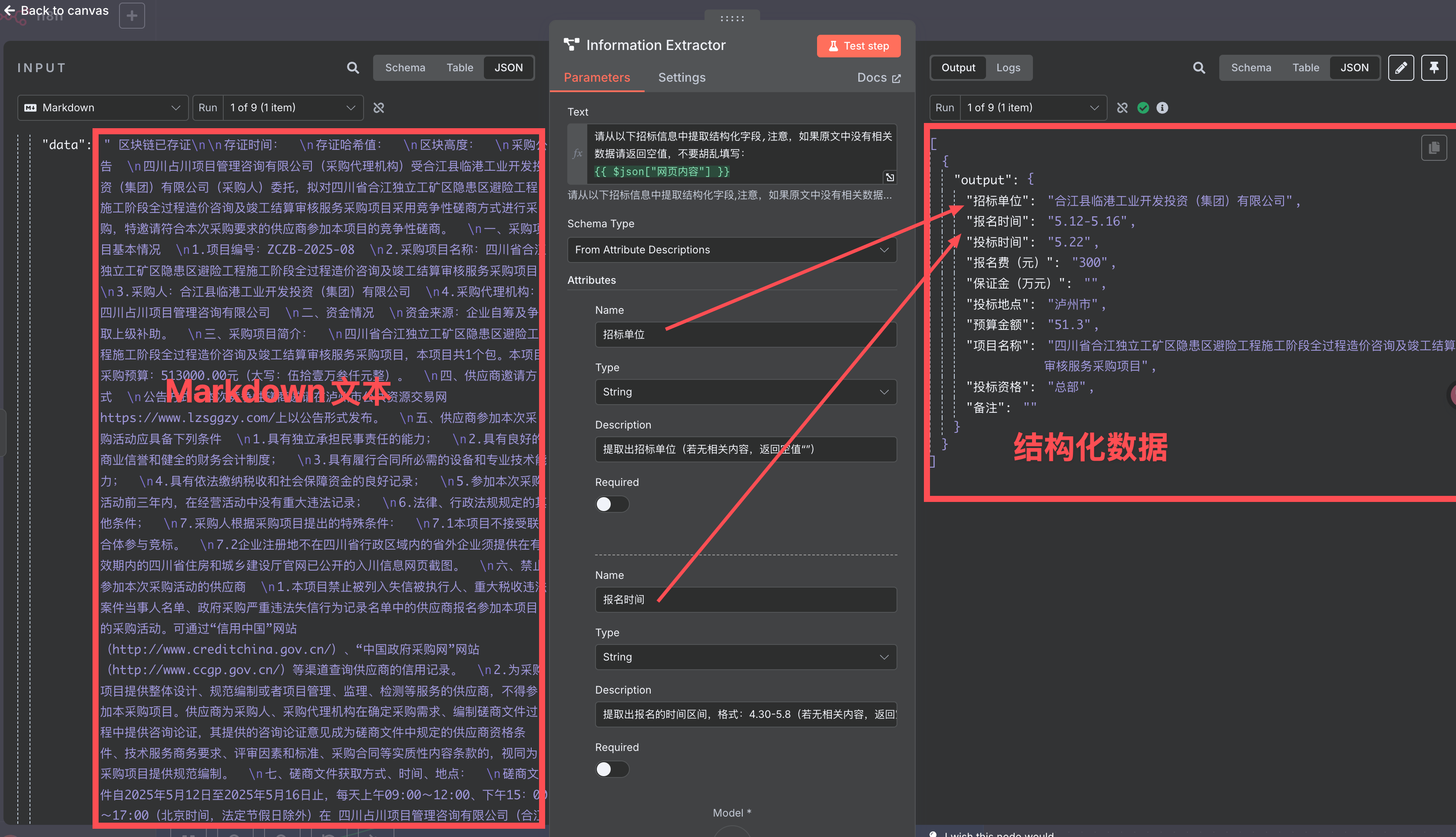
可以看到,我们可以自由定义需要的字段名称,以及对它的描述。
AI 会根据我们对字段的描述找出符号的值。
这个只需要一个节点就能完成,非常简单!
附件文件结构化信息提取
虽然我们上面在网页中提取出了公告的结构化信息,
但是有一些要求,比如报名费、保证金等它可以在附件中,
所以,我们还需要对附件的信息也做相同的结构化信息的提取。

只是中间增加了一些判断条件,
比如是否存在附件文件,存在才下载。
是否下载附件成功,成功才读取文件。
判断附件类型,区分 pdf 和 word 文件不同读取。
读取完后再用 information extractor 进行提取。
合并结构化信息
由于我们提取的信息可能有两个(网页和附件),
我们还需要将其合并成一个,保留有值的。
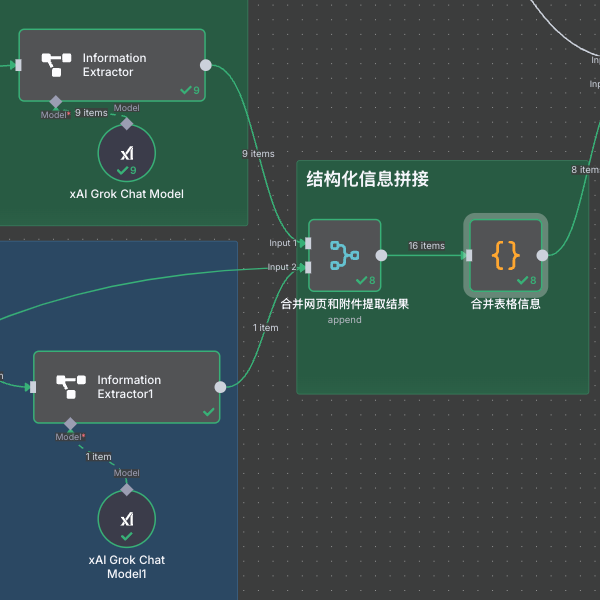
比如我建了一个 code 节点“合并表格信息”来进行合并:
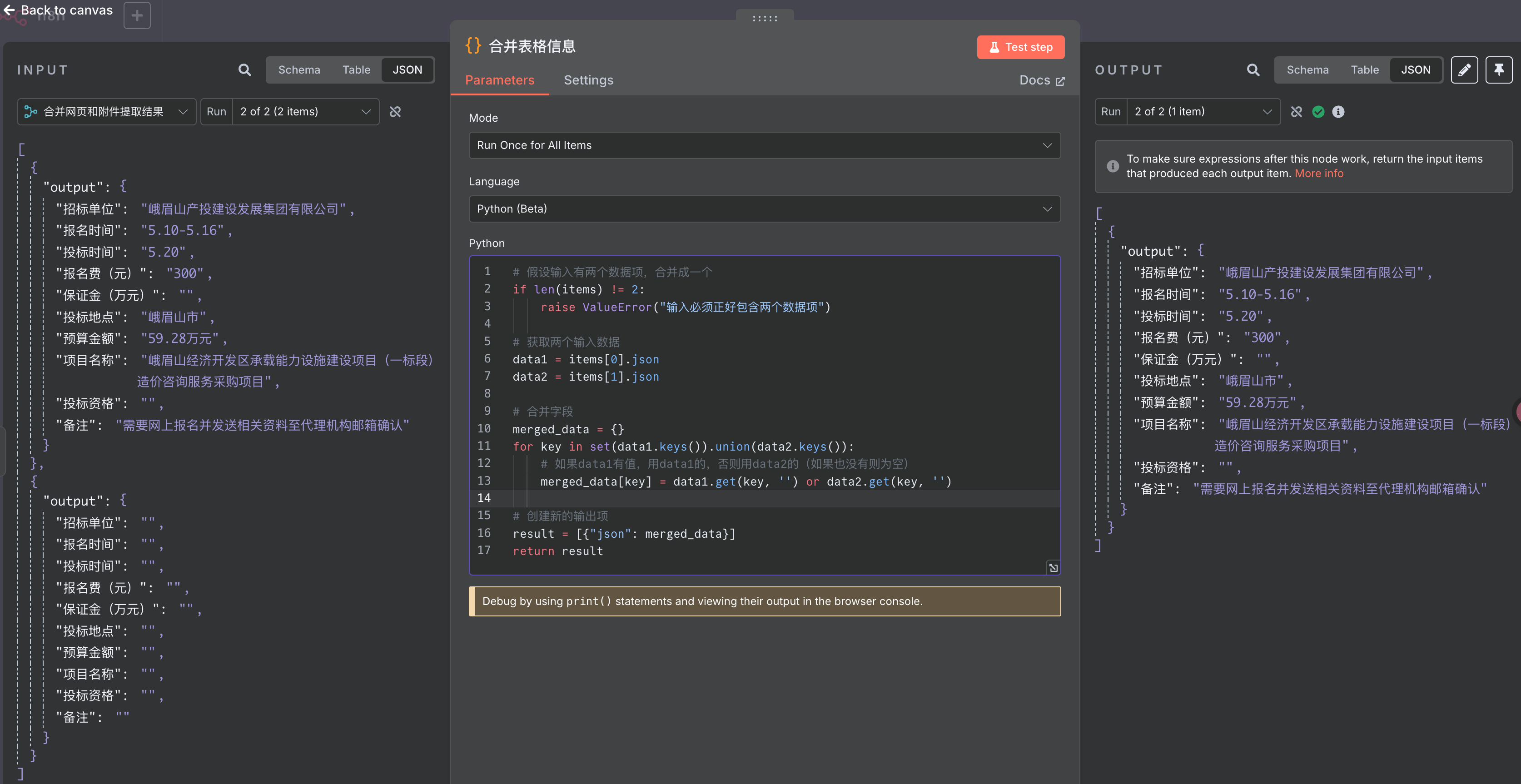
可以将左边两条信息,合并成一个。
整理信息、文件,发送邮件
我们将下面三路:
- 导出详情页 word 文件。
- 提取详情页结构化信息。
- 提取附件结构化信息。
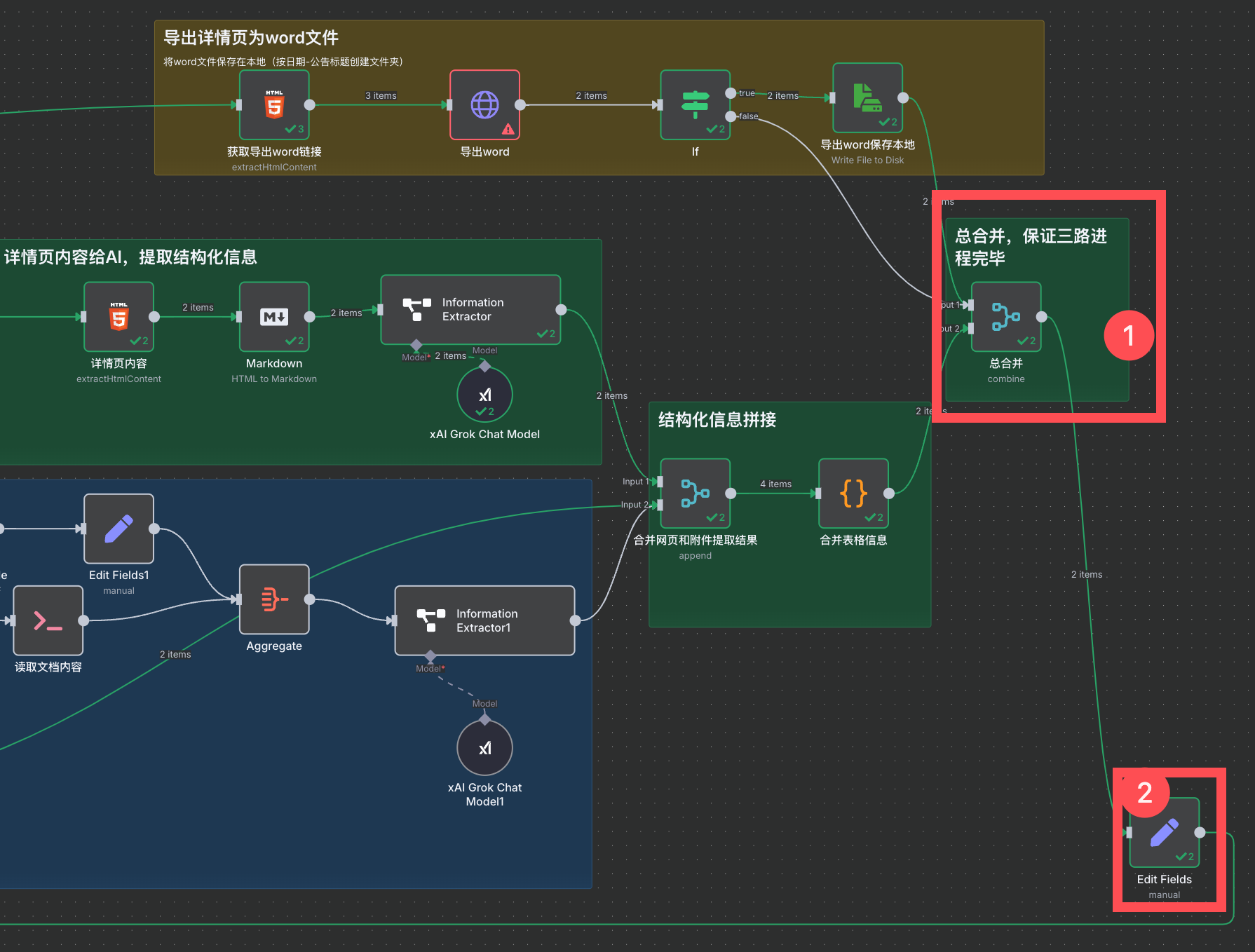
都执行完,连接一个 merge 节点(保证三路执行完毕),
用 set 节点筛选出需要的字段,再连接到 loop 节点上,
进行下一页循环。
Loop Done 后,连接后续的处理流程:
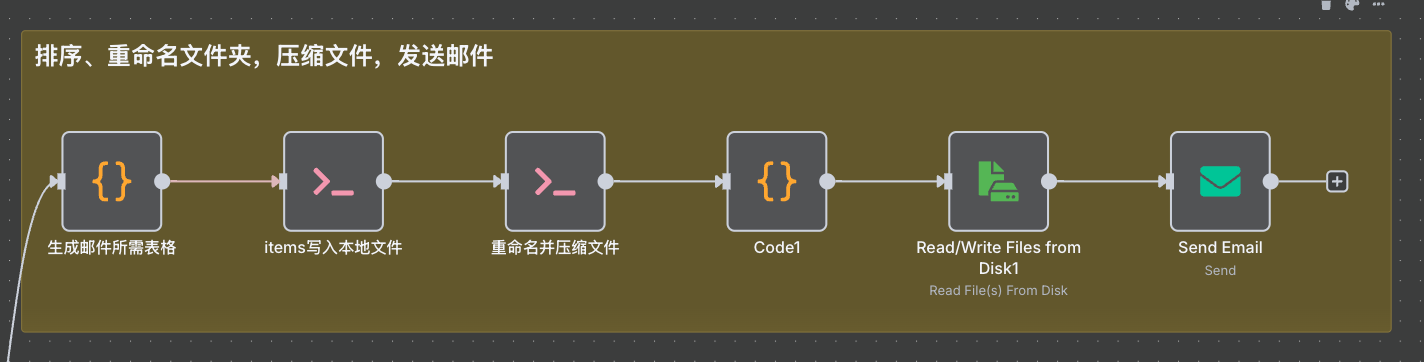
这里主要是将每条 item 信息,按同事的需求进行排序,
并生成 html 格式的表格。
再将本地的文件夹名称重命名添加上序号。
再将附件进行打包压缩。
再用 send email 结点发送出去。

同事收到的邮件信息如图所示(注:仅列示9条示例)
这样我们就将招标信息整理工作完全自动化了。
当然,这中间涉及到 n8n 中节点完成不了的,
我们都使用 code 节点,或者 execute command 节点进行处理,
前者可以运行内置的 javascript/python 代码,
后者可以运行操作系统的所有命令。
这样基本没有什么是不可以干的。