招标信息自动整理工作流(一)
昨天下班的时候,
业务发展部经理问我有没有收到当天的招标信息,
可能是所里邮箱系统有问题,她找我确认下。
聊了会,他们每天要安排一个同事花2小时整理招标信息,
邮件发送给分部所有经理和合伙人。
大概长这样:
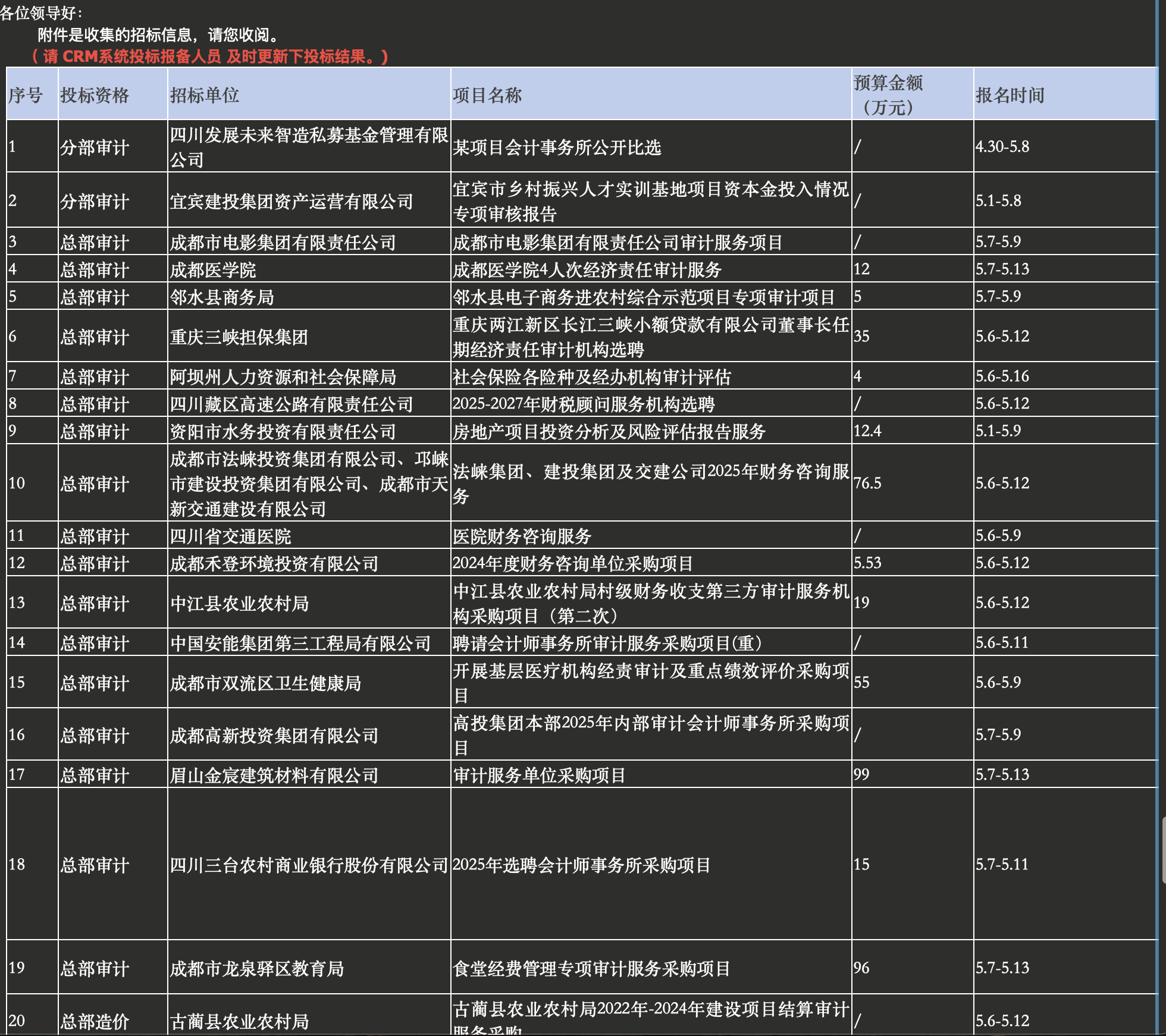
附件包含招标公告的附件( word ,pdf ) 等。
表格信息包含:
- 投标资格
- 招标单位
- 项目名称
- 预算金额
- 报名时间
- 投标时间
- 报名费
- 保证金
- 投标地点
- 备注
其中项目名称在网页上有信息,
其余大部分是人工在附件中查找的信息。
这不巧了吗?
最近我在学习 n8n AI 工作流,
这完全可以通过工作流完成:
公告信息及附件下载 -> AI 结构化信息提取 -> 邮件发送。
今天工作流搭建完成了一半,
我们一起来梳理分析如何完成。
数据源和原工作方法
这是税务部门付费购买的招标聚合信息会员,
同事每天会按板块去整理。
列表页如下:
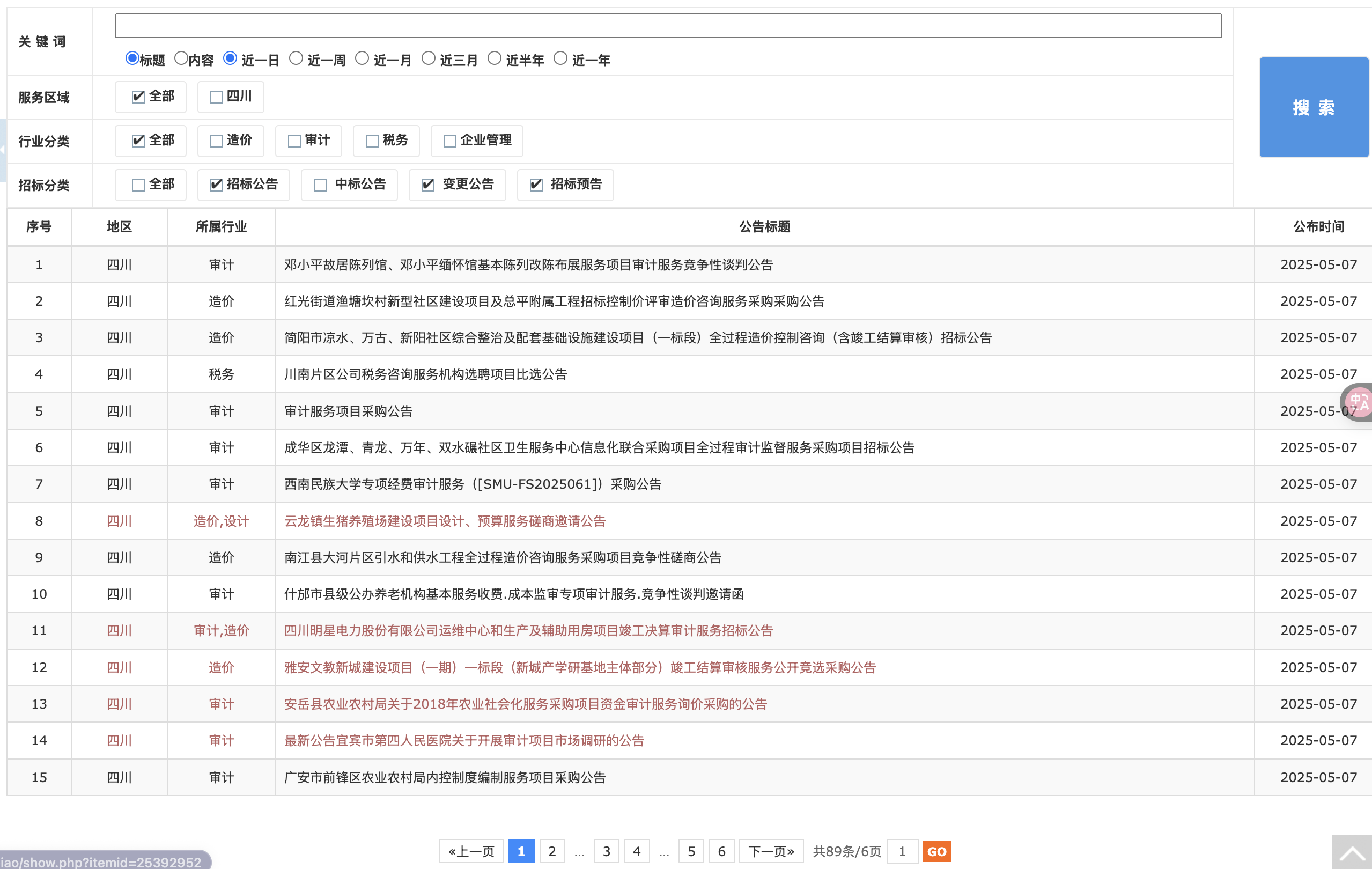
可以看到,我们通过这个页面,主要需要获取以下信息:
- 页码数:这样我知道需要请求多少页,保证数据完整性。
- 详情页链接:每个公告标题点进去就是详情页。
详请页如下:

我们需要获取如下信息:
- 点击“导出word按钮”:将详情页保存为 word 文件。
- 下载详情页中的附件:保存为本地文件。
最后同事再人工阅读复制粘贴整理表格信息。
将整理后表格信息和附件文件打包邮件发送经理、合伙人。
n8n 工作流
今天搭建的一半工作流还未涉及 AI ,
也就是说你完全可以用 python 等编程语言达到相同目的。
但 n8n 作为低代码平台,你完全可以用现成的节点拖拖拉拉完成。

获取招标信息列表页总页数
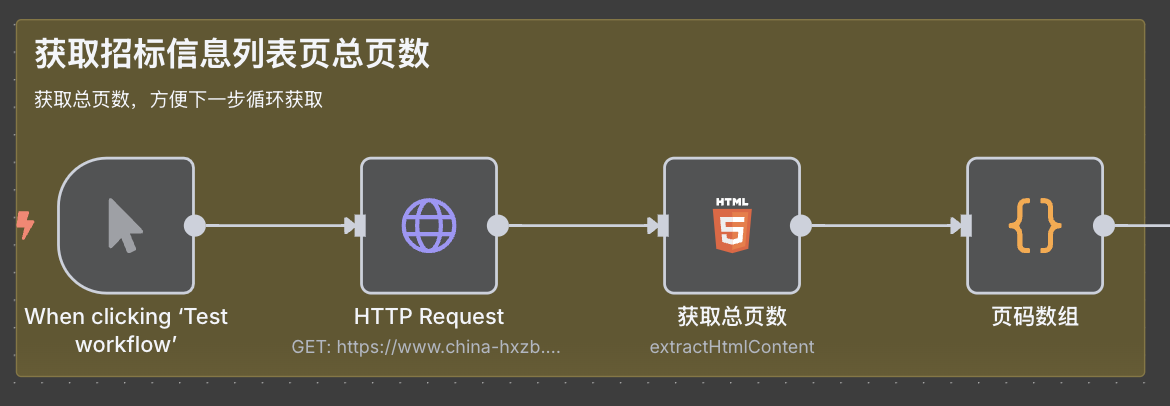
这里我们先要获取列表页总页数,
方便后续通过循环获取每一页的数据。
第一个手工触发节点在整个工作流调试完毕后,
可以换成 schedule 节点,能够做定时触发。
这里 4 个节点做的事情是:
触发 -> http 网页请求 -> html 节点提取出总页数 -> code 节点生成页码数组( 如:page:1-5 )
最后节点的页码数组如下:
[
{
"page": 1
},
{
"page": 2
},
{
"page": 3
},
{
"page": 4
},
{
"page": 5
}
]循环获取详情页链接
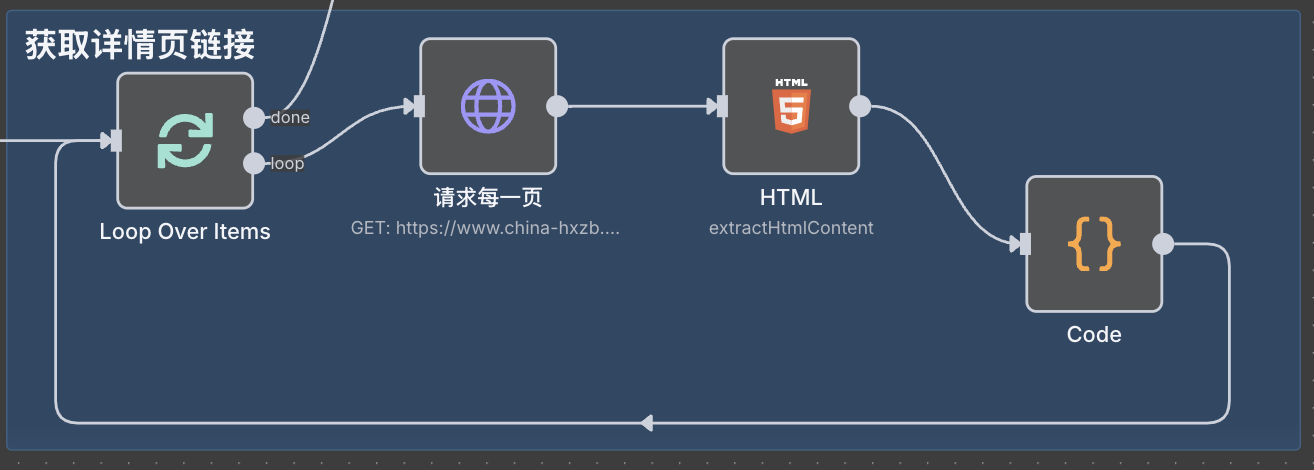
这里 4 个节点作用如下:
循环 page 页码 -> 请求每个列表页 -> html 节点提取招标列表信息 -> code 节点提取 items
loop 节点完成后生成如下 items:
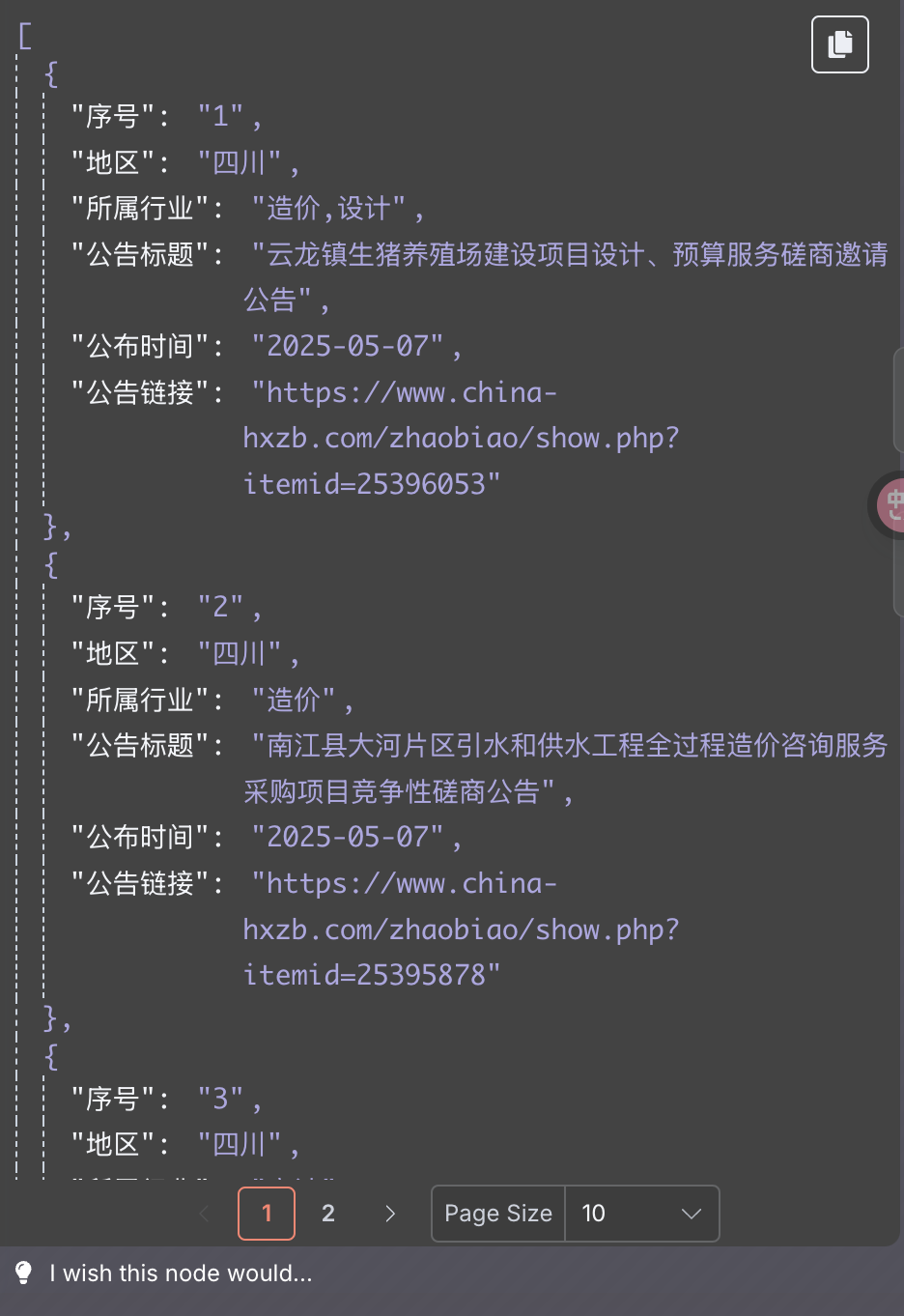
供后续循环获取详情页信息。
请求详情页
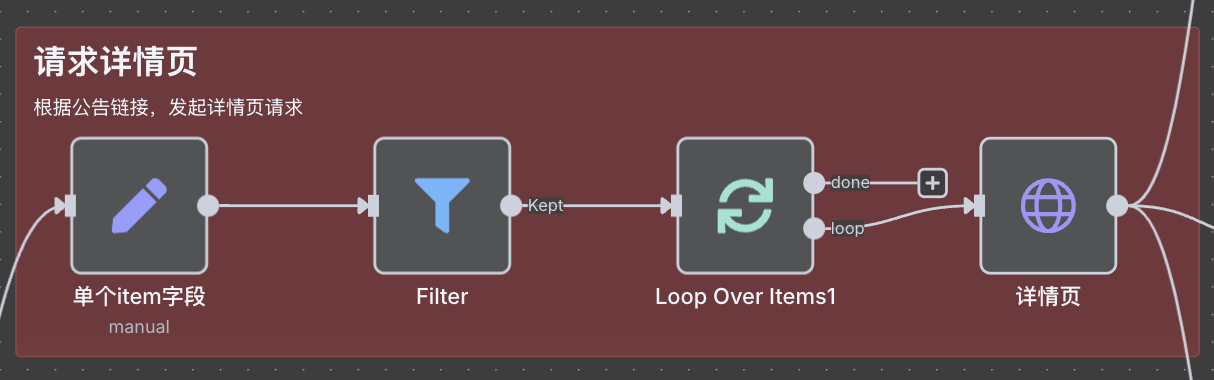
这里 filter 筛选节点,主要是调试用(筛选想要的特定详情页),可以忽略。
这里循环每一个 item ,发起每一个详情页的请求。
详情页处理
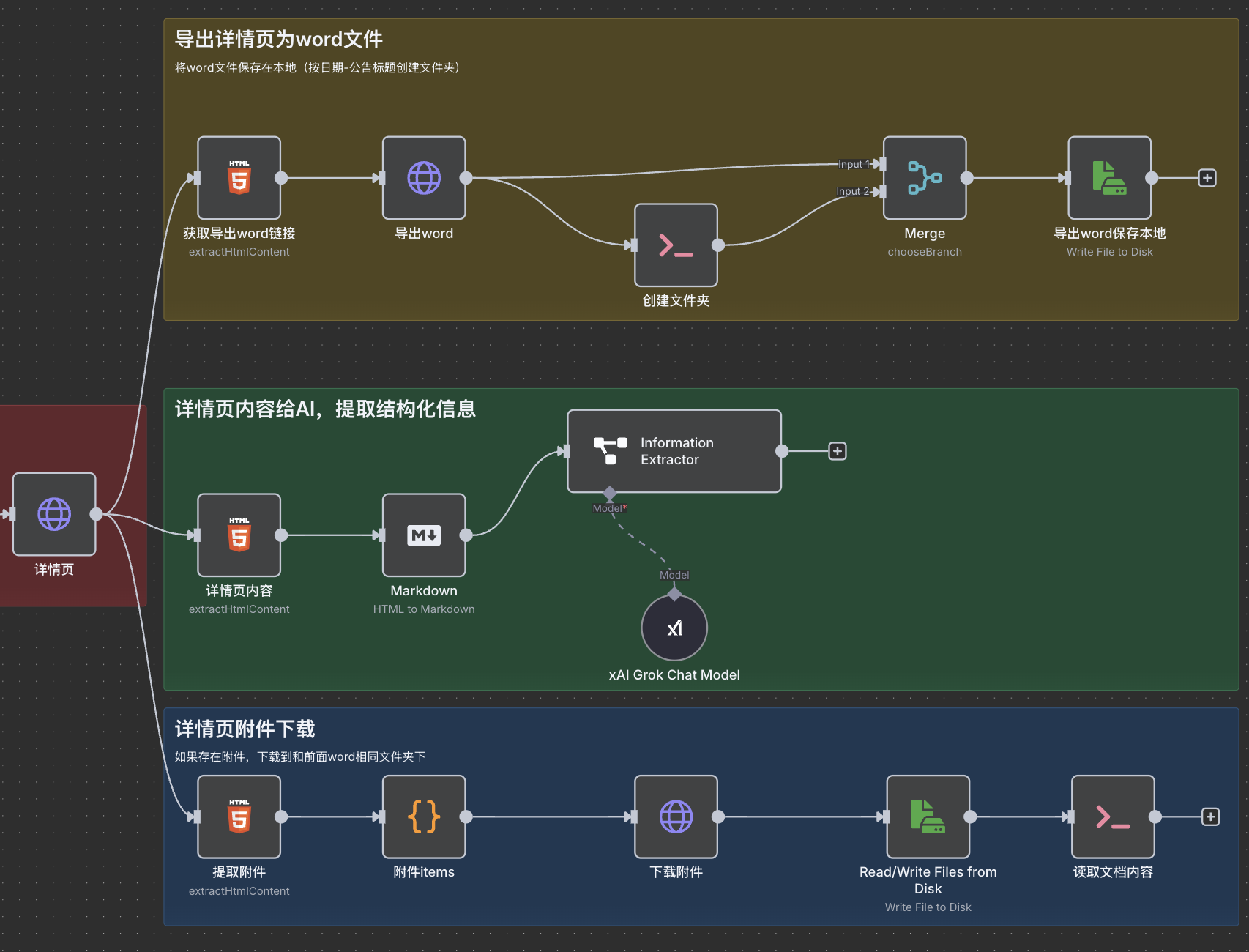
针对详情页,我们分三路进行处理:
导出详情页为 word 文件
相当于我们把详情页点击“导出word”,
按“日期-公告标题”创建本地文件夹,
把word保存到该文件夹中。
详情页内容提取结构化信息
这里,我们将详情页转成AI更容易阅读的 markdown ,
给结构化信息提取的 agent ,利用 grok AI 大模型的能力,
提取出结构化信息:如报名日期,预算金额,投标时间等。
( 注:今天调试的时候超过网站浏览限制了,
提取结构化信息还未完成)
详情页附件下载
有些招标公告中是存在附件的,
我们需要将其下载下来和详情页保存的 word 文件保存在相同目录。
当然,后面也同样需要将其利用 AI agent 提取出结构化信息。
( 暂未完成 )
后续处理
其实前面我们已完成大部分工作了,
后面就是需要利用 AI 提取结构化信息,
然后整理成表格,
将表格和本地文件利用邮件节点发送出去。
这样就可以每天定时处理,不再需要人工进行了。
使用成本

n8n
开源免费,可以自部署在自己服务器或者电脑上。
服务器
上个月我买了一台香港的永久云服务器,3980元,
CPU 8核,内存 16G ,系统盘 50 G ,硬盘 90 G ,带宽 30M 。
主要看重服务器的固定 IP。
只要 10 年不跑路,我就赚了。
API
调用大模型需要使用 api ,
前面领了 grok ai 每个月 150 美元的免费额度(需要数据共享),
处理这类公开资料数据,完全用不完。
所以,实际上,搭建这样的工作流几乎是零成本。
结语
类似 n8n 这样的 AI 工作流值得大家去学习的,
它像一个放大器,能够放大一个人的能力,提高效率。
一个工作流就像一个员工,你可以拥有无数这样的员工为你工作。
假如,你每天的工作还是类似这样低级化的工作,
那么不用等到未来,现在其实就可以把你的工作替代掉。
除非你在做给人提供情绪价值的工作,
这个可能不会被替代,
那么你应该思考,如何利用 AI 这个放大器,
与自己的专业知识、业务技能结合起来,
无限放大自己的能力。