合同、权证、纳税申报表批量识别!审计工具箱v0.6.8更新
昨天文章更新了 v0.6.7 版本,在全局的“参数设置”模块添加上了 AI 的API ,
今天和AI聊了一天,把之前的“文本文件关键信息提取”功能升级了下,
由之前只支持 txt/markdown 文本文件,拓展到支持 pdf/图片类文件了。
可以批量提取合同、权证、纳税申报表等各类单据。
项目组不要再让实习生录合同、录单据了!!!
让工具跑一遍,让实习生检查、更正录入结果。
下面说下操作步骤:
注册AI平台账号
你可以随意选择兼容 openai 格式的 api 的平台。
这里我们以阿里云百炼为例:
网址:https://bailian.console.aliyun.com
首次注册每个模型会赠送百万token。
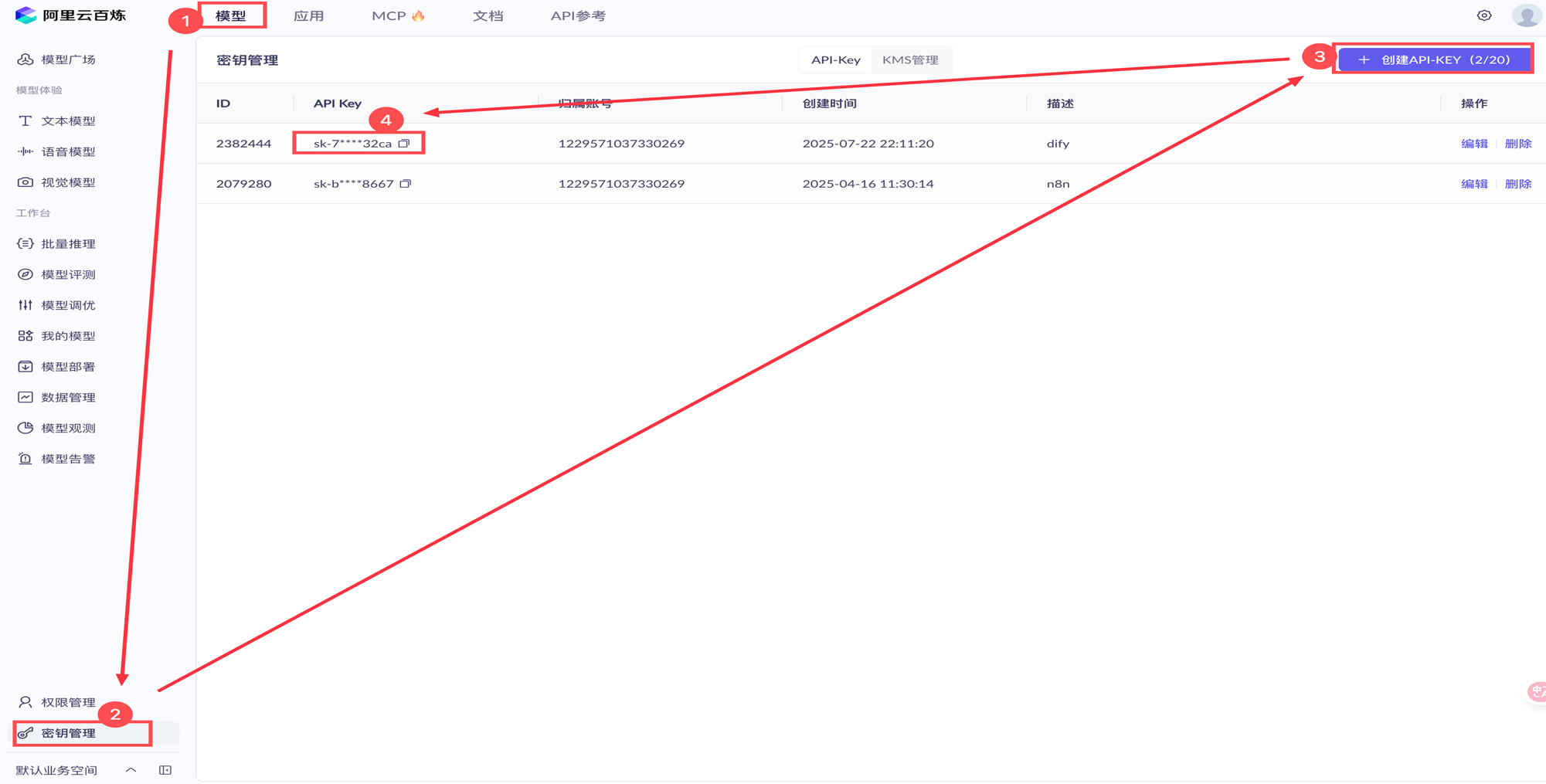
在“模型”-> “密钥管理” -> “创建API-KEY”
复制好创建的 API-Key 。
工具箱填写 API-key
扫码加入下面免费知识星球“审计军火库”:
在置顶链接中,下载“审计工具箱”。
解压后,运行工具箱。
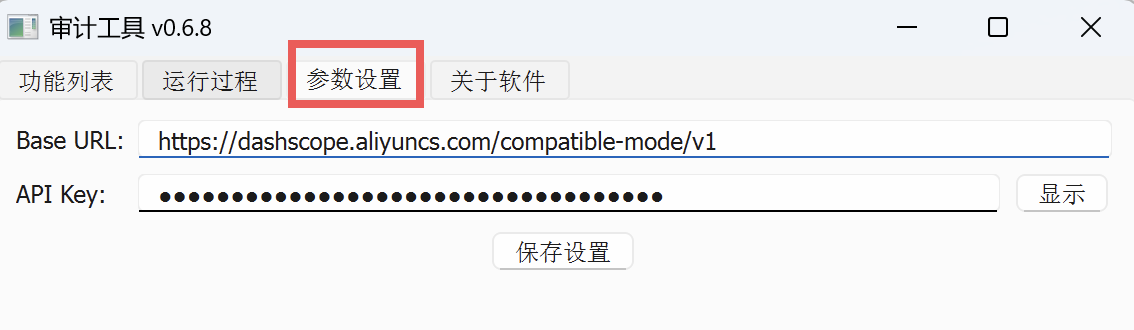
在参数设置中填写好 base_url 和 api_key:
base_url:https://dashscope.aliyuncs.com/compatible-mode/v1
api_key: 上个步骤的 api-key 复制粘贴过来。
点击保存设置。
保存后,会在工具箱文件夹根目录中新增加一个config.json的文件,里面存储了base_url和api_key,
切记不要将该文件直接拷贝给他人,可能会造成别人消耗你的token,导致钱的损失。如果已经发生泄露,可以阿里云百炼平台上去删除这个api key.
配置表参数填写
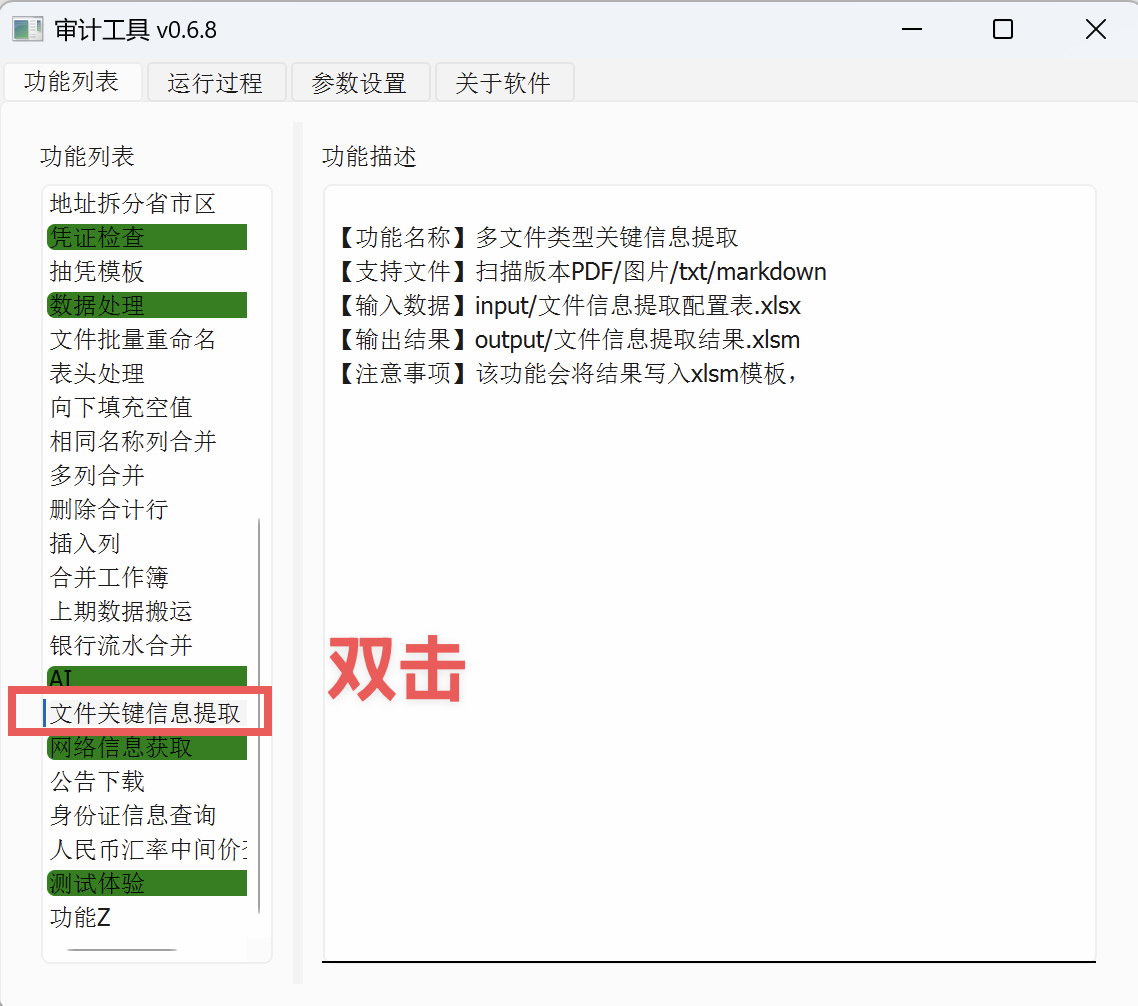
在工具箱的功能列表中,双击“文件关键信息提取”:
点击“填写数据”:
在打开的配置表中填写参数:
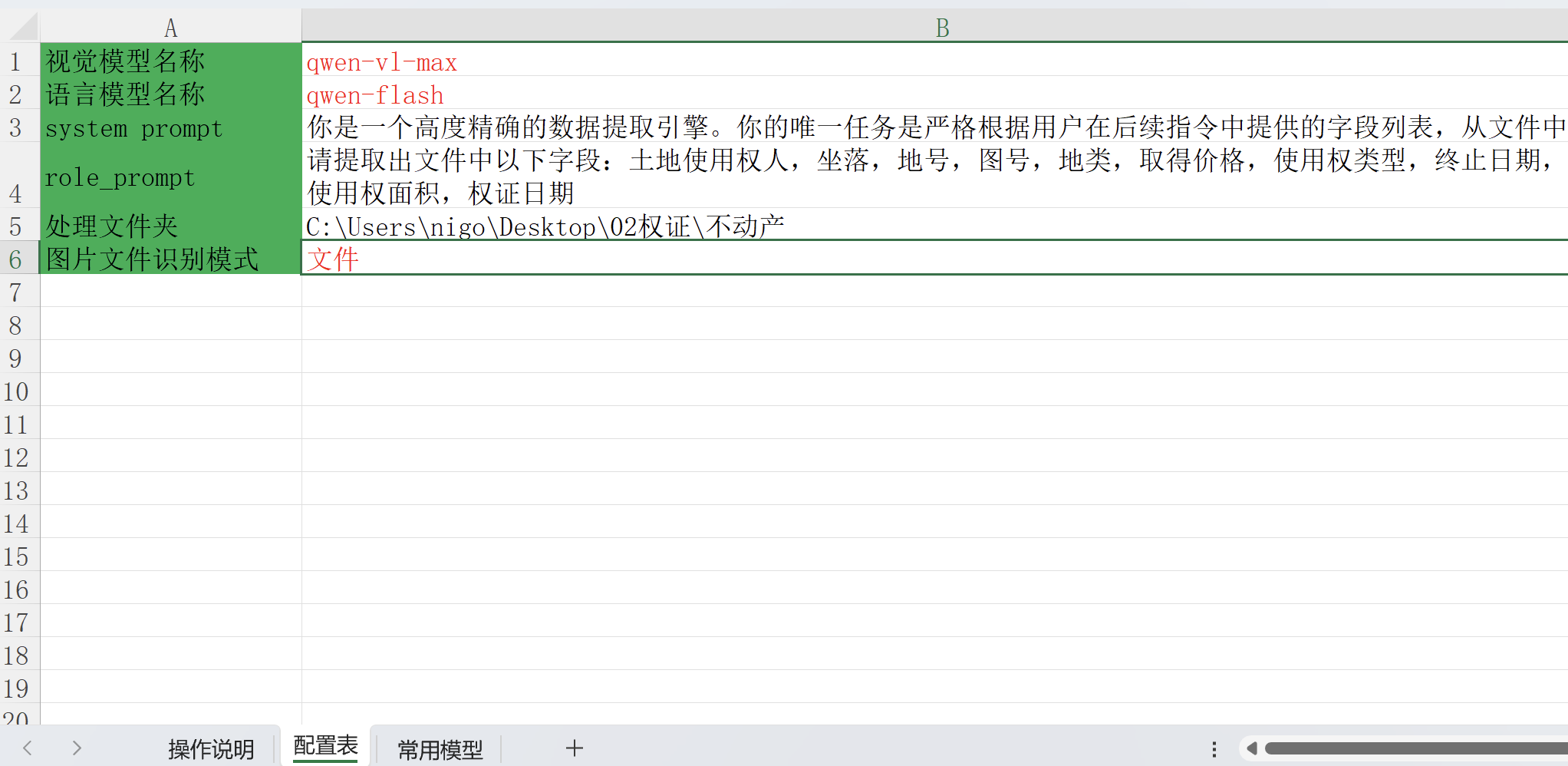
其中“视觉模型名称”是处理扫描件 pdf 和图片的,最强的是 qwen-vl-max ,
“语言模型名称”是处理 txt/markdown 文本文件的,最强的是 qwen-max 最快的是 qwen-flash ,中间的是 qwen-plus ,自行选择。
symstem_prompt: 这个系统提示词尽量不要改,目前是和我代码处理是有关联。
role_prompt: 这个用户提示词需要根据你的材料进行修改,比如你想提取什么字段就可以列示在这里,如果有些字段复杂还可以添加一些描述来说明要提取的字段的含义,这样可能更准确。
处理文件夹:你需要提取信息的文件所在文件夹,可以多层级。
图片文件识别模式:如果你要处理的文件中存在图片,选择“文件夹”代表一个文件夹下的所有图片视为同一个文件,选择文件则每张图片视为一个文件。
参数就这么多,需要修改的其实就: role_prompt 、处理文件夹、图片文件识别模式 。
填写好后,保存下配置表。
运行程序
点击“开始运行”:
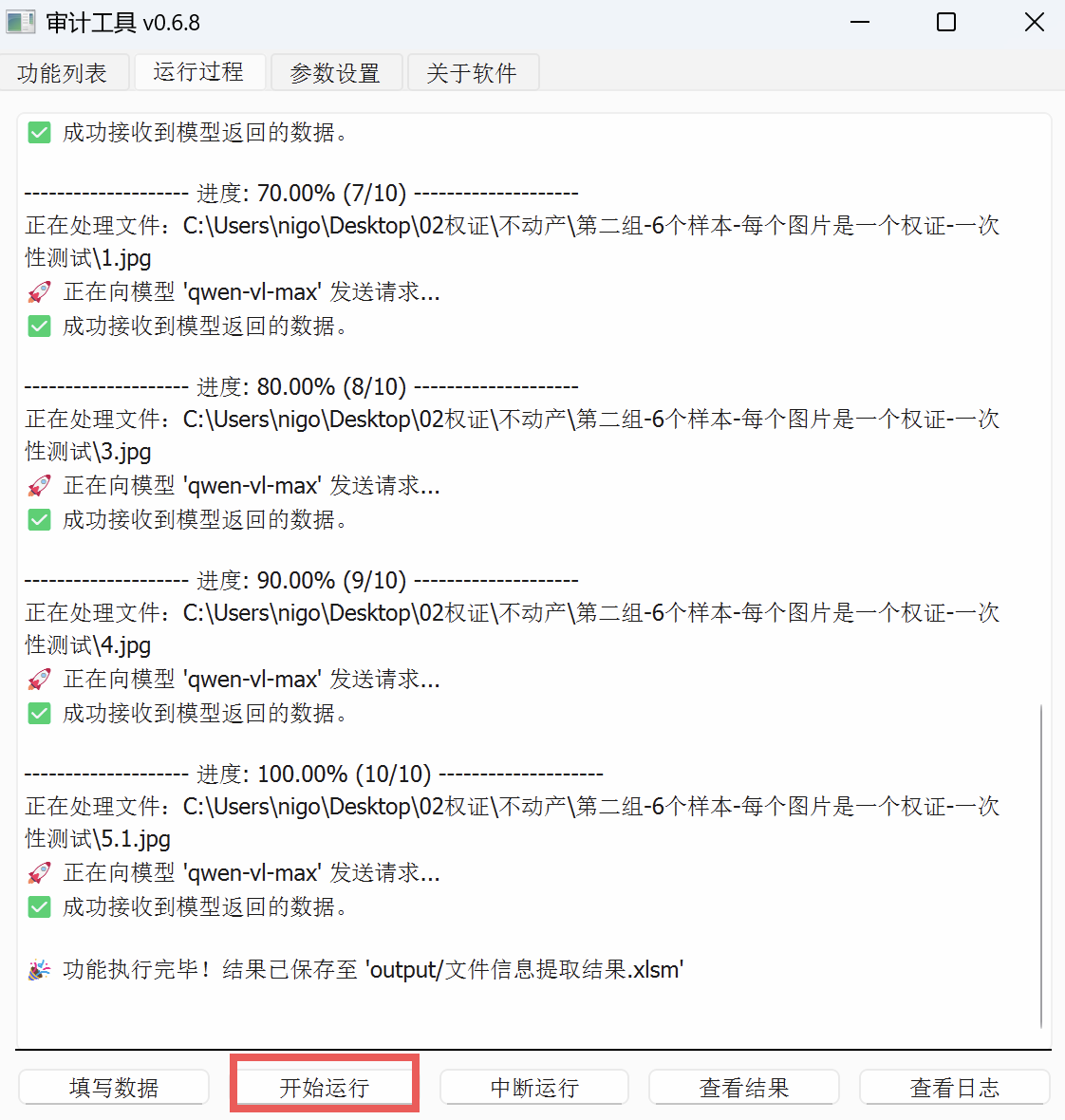
程序会根据不同的文件类型决定调用视觉模型还是语言模型,
执行完毕后,点击“查看结果”按钮,打开生成的文件:

生成的这个文件是带 vba 宏的,我们想对照原始文件进行检查的话,
直接双击 A 列,会直接打开对应的文件,这样我们就可以方便的核对检查。
特别说明
对于有复杂的页面结构的单据,建议使用视觉模型,直接对 pdf 或者图片进行识别,
这样准确率较高,只是速度比较慢。
对于页面结构不复杂的文本内容,如合同,建议先本地将 pdf 或图片 ocr 转成 txt 文件,
再对 txt 文件进行识别,这样会使用大语言模型,
这样速度很快,准确性一般也没有问题。
调用视觉模型调用 API 时,上传的是拆分开的图片,
调用语言模型调用 API 时,上传是文件中的文本(非文件)。
扫码加入免费的知识星球,在置顶链接中有审计工具箱的下载网盘链接。
也欢迎大家在星球中反馈 bug ,提新的需求。
信永中和的同事也可以通过企业微信向我反馈。
阿里云折扣和咨询
下面二维码是阿里云的经销商(不是狗哥!),相比官网直销有一定折扣,
有需要的可以扫码咨询(备注:=狗哥推荐= ):
没需要的话,直接阿里云百炼官网注册就行。
另外,如果对数据安全或者企业的AI方案,也可以通过她咨询,
可以安排阿里云的架构师解答。