利用AI手搓《风险评估与客户环境RACE》底稿自动生成工作流
审计作业中以往依赖于人去判断选择什么工具,进行怎样的处理。
如:网页搜索,阅读资料,Excel数据处理,材料编写等。
在使用传统代码编写时难以做到通用性,
而 AI 可以代替人的大脑,自主选择工具,进行相应的处理。
这样,审计过程中的很多工作的自动化将变成可能。
本文,我们以相对容易的《风险评估与客户环境RACE》底稿为例,
来进行探索如何利用 AI 手搓一个底稿自动生成工作流。
下面以信永中和的底稿样式为例:
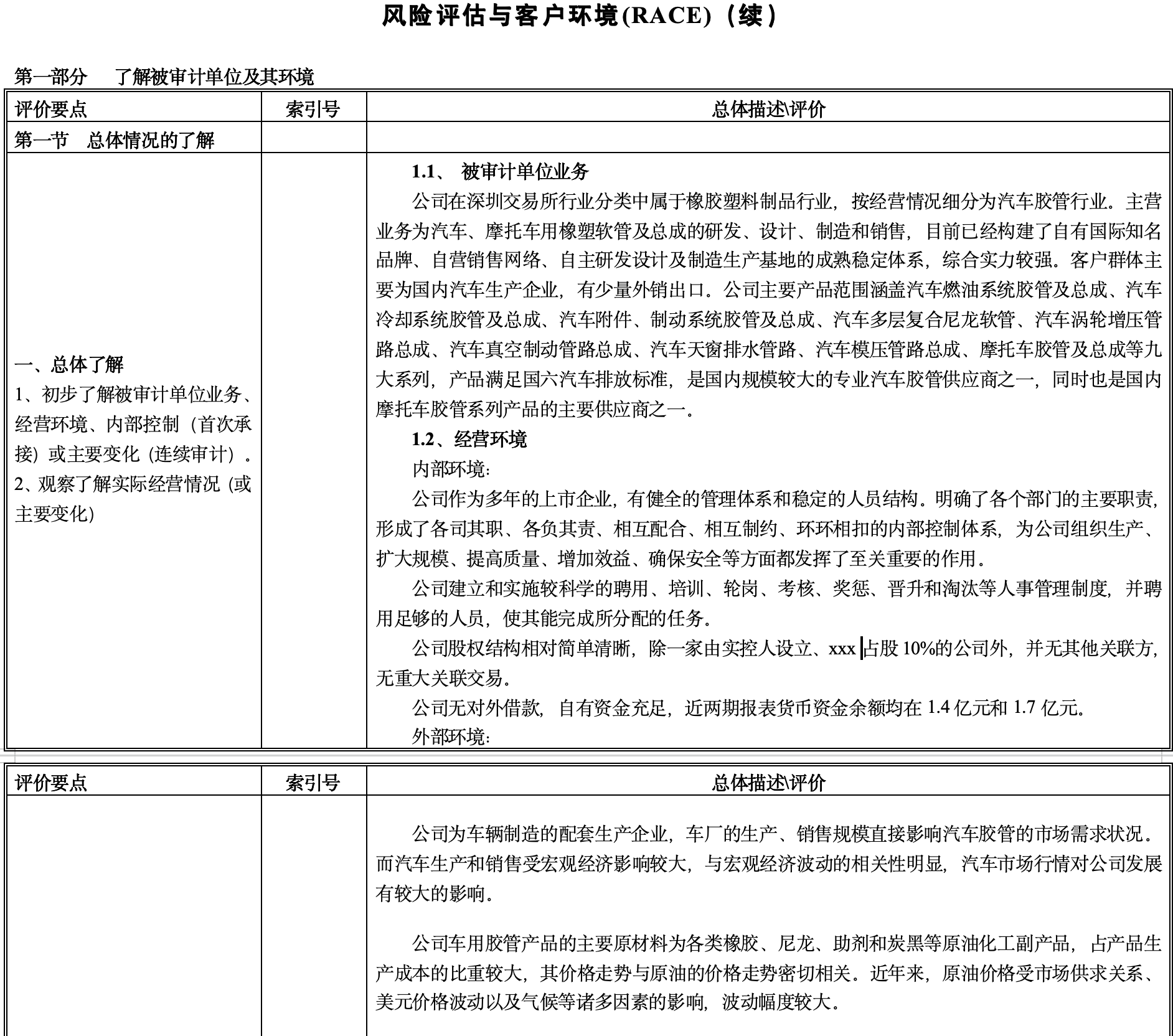
第一性原理思考
总结起来,这张底稿主要干的事情,通过搜索引擎搜索网络资料,阅读整理,风险分析。
无非就是有几十个不同的问题需要进行操作。
那我们就可以将整个工作流设计如下:
- 底稿拆分成几十个小问。
- 每个小问调用通用的“网络搜索工作流”,得到每个问题的答案。
- 将几十个问题答案整合成结构化数据。
- 将结构化数据执行 Python 代码,填充入Word模板文件,生成底稿。
怎么样,我们这样就将一个看似复杂的问题,转化成了一个可执行的问题。
对于理工科来说,只要你把问题拆分得足够小,就没有什么解决不了的问题。
网络搜索工作流的搭建
我们利用 n8n 来搭建一个基础的网页信息搜索的工作流,
后面拆分出的每一个问题,我们都是通过它来获取答案:

下面是我在 AI Agent 节点中输入的 system prompt:
你是一个网络信息搜索助手,根据用户提问,获取网络信息回答用户问题:
必须进行网络搜索,不能直接回答用户问题,因为用户需要最新的、准确的网络信息。
## 操作步骤:
- 使用 `date` 工具获取当前日期,并在搜索时优先选择近期资料(建议限制在最近一两年),以保证信息的时效性。例如,在搜索查询中加入时间范围,如“过去一年”或“最近两年”。
- 复杂问题先调用sequential-thinking工具进行任务规划。
- 利用 Searxng 进行网络信息搜索。搜索时,使用中文关键词,但在涉及专业术语时保留英文(如“machine learning”),以兼顾搜索的广泛性和准确性。建议使用关键词、短语或问题形式构造查询,以提高结果的相关性。
- 使用 `fetch` 获取网页详细信息。从搜索结果中选择最相关、最可信的网页进行提取。如果某个网页无法获取,请尝试其他相关网页,或通过 Searxng 扩大搜索范围,直到找到足够信息解答用户问题。
- 在回答用户问题时,基于搜索到的信息,提供准确、简洁的答案,并引用来源(如网页链接或出处)以增加可信度。
- 如果搜索结果不足或无法回答用户问题,请诚实地告知用户,并建议他们尝试其他搜索关键词或来源。
需要说明的是,这里主要是利用了 “SearXNG” 节点,来访问我本地搭建的服务,去获取浏览器搜索的信息,
它会返回搜索文章的链接和概述。
其次是在 “MCP Client” 节点中,我用到了 fetch mcp 将上面搜索出的网页链接获取内容文本。
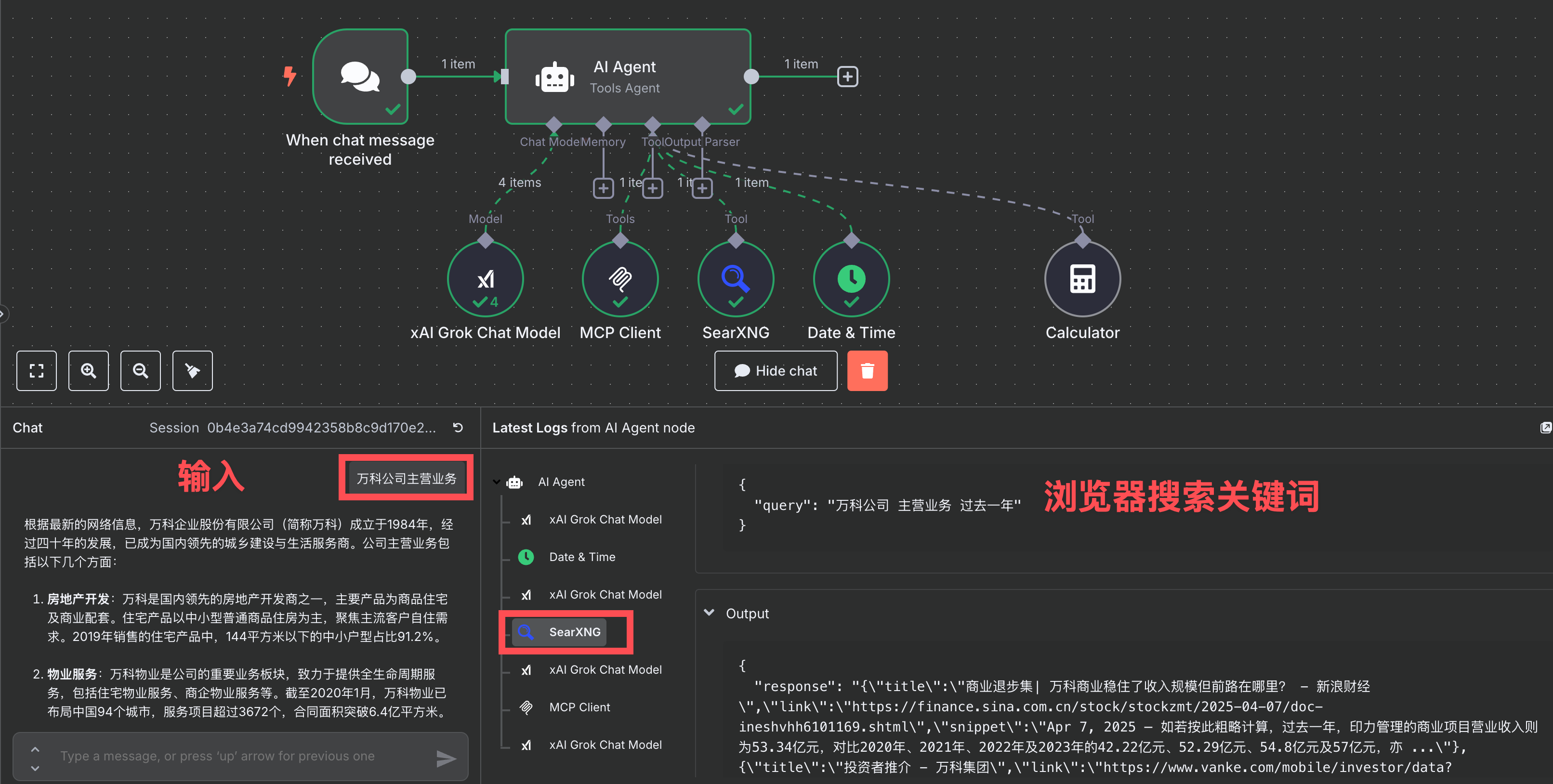
为方便理解,例如,当我们输入一个问题“万科公司主营业务”,
AI Agent 收到问题后,会自动用 SearXNG 搜索“万科公司 主营业务 过去一年”,
将搜索到的网页链接交给 fetch 工具获取网页详细内容,
整合后就返回我答案。
这就是我们最主要底层功能,搭建起来也非常简单。
底稿拆解为小问题
如下图标红节点,就是我们将底稿拆解成一个个小问题,
每个小问题对应一个单独的 prompt ,
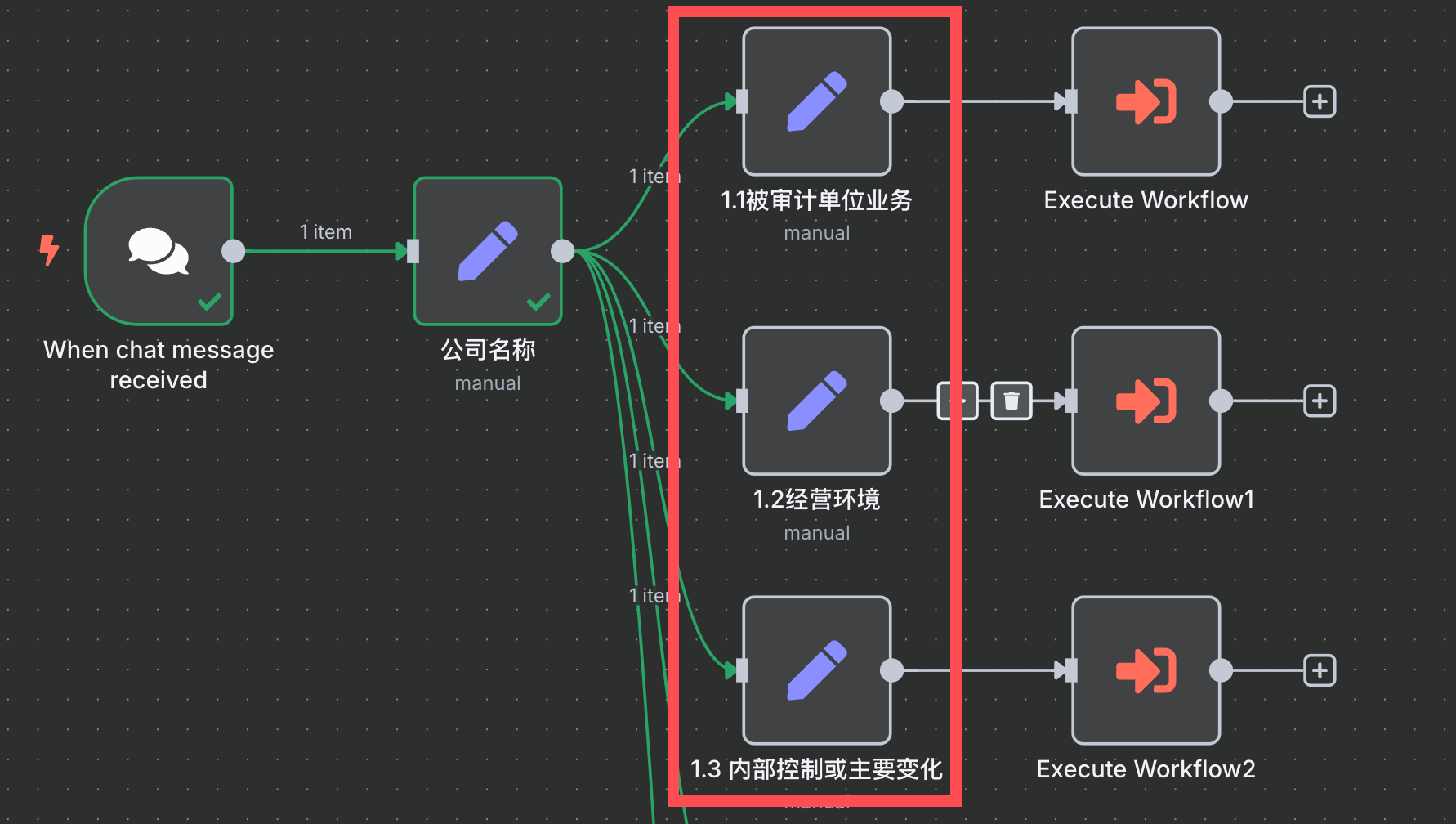
每个小问题的 prompt 都会调用前面我们的“网页搜索工作流”,
生成我们想要的答案。
这样拆分也有一个好处,就是你可以通过控制提示词( prompt ),
来精准控制 AI 回答你的结果。
当然,有些相似的问题你也可以结合在一起。
比如,这三个小问题:
- 被审计单位业务
- 经营环境
- 内部控制或主要变化
我发现它搜索的时候经常都是搜索到年报,这个消耗 token 比较大,可能合并在一起比较节约。
我们就以这节为例,看看提示词:
{{ $json.chatInput }}的总体情况了解,请搜索并回答以下问题:
1.1 所属行业分类(如果有细分行业用细分行业,优先用证券交易所的行业分类),客户群体,主要产品。组织成一段话,不加任何引导语或额外说明。
1.2 经营环境(不需要财务情况),分为内部环境和外部环境。不加任何引导语或额外说明。
1.3 内部控制及业务经营重大变化事项。组织成一段话,不加任何引导语或额外说明。
输出结果示例: ## 1.1、 被审计单位业务 {回答} ## 1.2、经营环境 {回答} ## 1.3、内部控制或主要变化 {回答}
注: {{ $json.chatInput }} 为用户输入的公司名称。
我们这三个问题执行后的答案如下:
包含了回复答案和检索来源:

为了更好阅读,我将答案显示下:

特殊逻辑的处理
虽然整个底稿大部分问题,都是通过网页搜索来获取信息。
但也有些特殊的,我们只需要针对其做一些变动。
还是那句话,当我们将问题拆分得足够小,就一定可以解决。
比如,财务报表分析,我并不希望它通过网络文章的零碎信息中去总结,
而是想获取准确的财务报表数据。

这里其实又可以再分成两类:
- 上市公司,获取公开财务报表数据。
- 非上市公司,企业提供未审报表数据。
我们以上市公司为例,我首先通过爬虫将历年的上市公司财务报表数据存到 mysql 数据库中,
以供工作流调用。
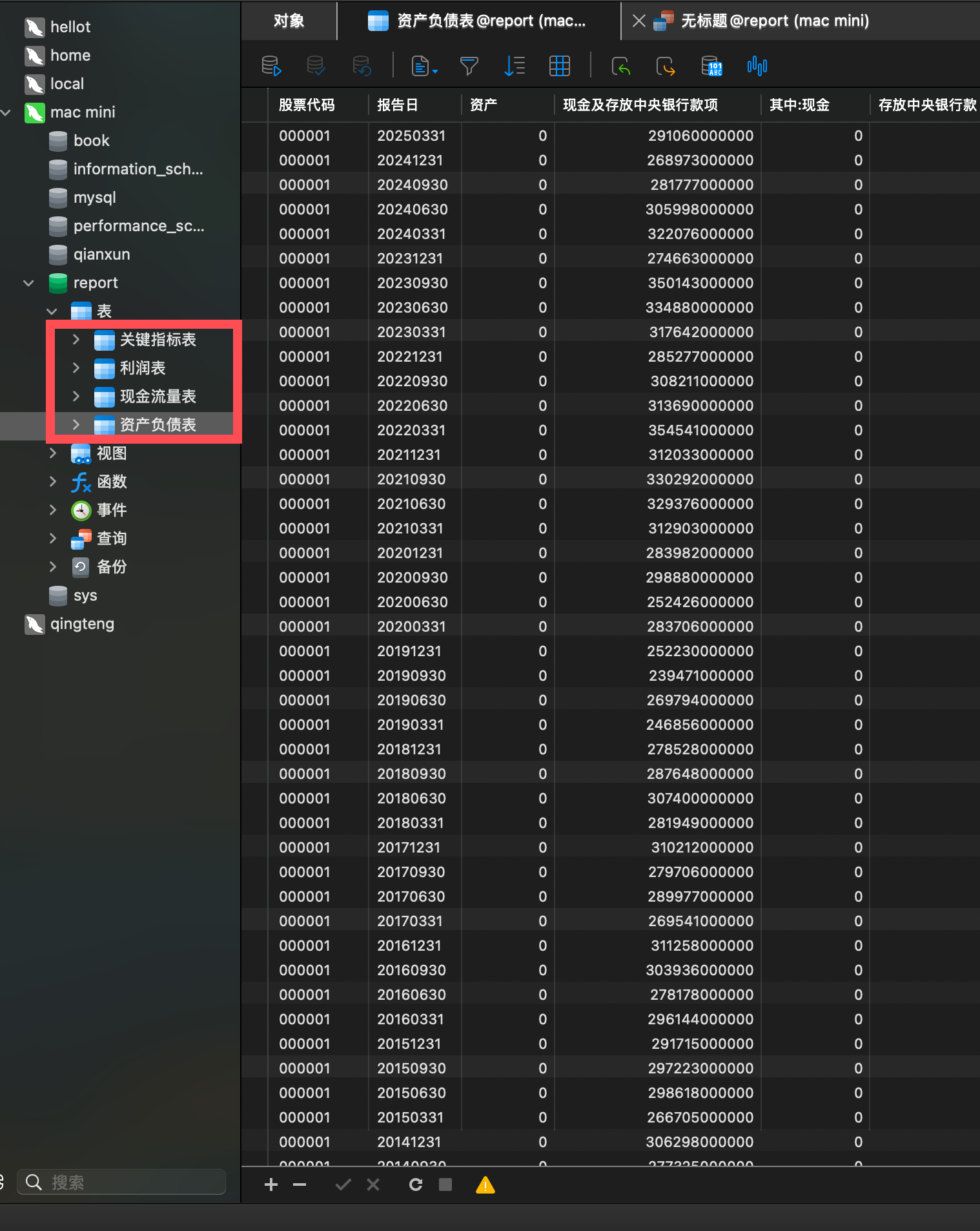
财务报表分析这几个问题,我就单独给他配一个处理 AI agent,
区别就是能够获取我 mysql 数据库的数据。
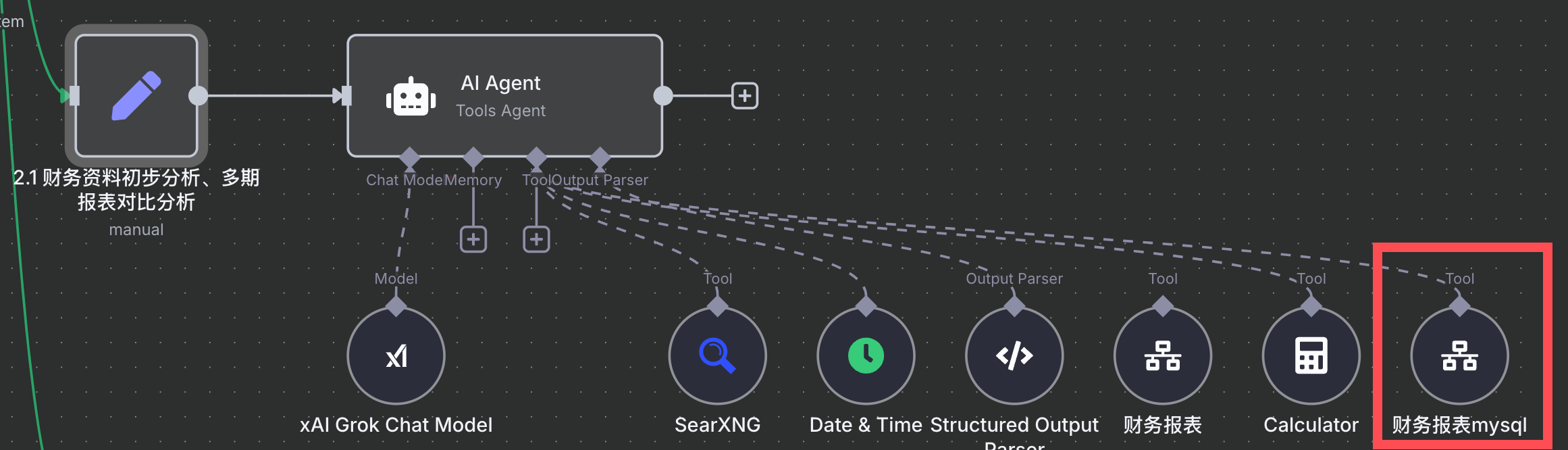
set 节点(上图左1)中的提示词( user prompt )如下:
{{ $json.chatInput }}根据最近两年的主要财务指标进行分析,以注册会计师的审计视角进行风险评估,回答以下问题:
- 财务资料初步分析、多期报表对比分析
- 与行业关键数据对比分析(先搜索找到该公司的可比公司或主要竞争对手,需要是上市公司),用“财务报表mysql”工具获取财务数据,再将最近一期进行对比分析。
数据分析不要依赖网络搜索,直接使用获取到的数据进行分析。
输出结果示例: ## 1、2、财务资料初步分析、多期报表对比分析: {回答} ## 3、与行业关键数据对比分析 ## 总体评价
工作流对该问题执行后的输出:

( 注:下方显示了来源 source 为:财务报表数据来源于财务报表mysql工具,行业对比数据基于searxng-search工具获取的可比公司信息和财务报表mysql工具获取的最新财务数据。)
我们将其更友好的显示下:

类似的,像券商研报等,它依然可以通过浏览器获取,阅读,分析,整理。
你需要做的就是提示词精准控制。
整理成结构化数据
前面我们是将一个底稿都转成了小问题,
得到了几十个答案,
为了最后生成 Word 底稿(按所里格式要求),
我们需要先将整理成结构化数据。
其实最简单就是写成类似下面表格结构:
| 编号 | 回答 | 来源 |
|---|---|---|
| 1 | xxx | xxx |
我们可以用 set 节点和 code 节点完成,
输出成一个 Excel 文件。
生成 word 报告
我们可以专门写一个 python 文件,
用来将 Excel 中的回复根据编号填充到 Word 指定位置。
在 n8n 中我们只需要用 Execute Command 节点就可以执行这个 Python 文件,
生成最终的 word 底稿,供用户下载。
结语
需要说明的是,上述步骤,你都可以手工利用 DeepSeek ,通义千问,达到相同效果,
只是你得每个问题写提示词,不停复制粘贴。
而这个 AI 工作流的意义,就在于省去这个人工步骤,
只需要输入公司名称,就等着运行结束拿报告。
当然,后续还需要你人工进行修改调整。
其实通过这个例子,也可以看出了,AI 在我们审计工作中是可以落地的,
有无数有小场景是可以做的。
当然,本文中面临一个严峻的问题就是 token 数的消耗,
比如,它如果检索出一篇年度报告,阅读下来就会消耗个 10万 token ,
整个底稿下来,消耗的 token 数可能巨大,
有待评估其一份底稿下来的综合成本。
不过目前 token 的成本越来越便宜,
目前 100 万 token 也就10 元钱,
就算消耗个200万 token ,也就 20 元(目测消耗不到那么多)。
可以预见的未来,
AI 会对审计效率极大的提升,
也会对审计组织模式和作业模式带来巨大的改变,
这一天越来越近。