牛逼了!AI 视觉模型运用在审计场景中
阿里开源的通义千问的视觉模型是非常牛逼的,
在年前他又开源了 qwen2.5 vl 模型,对于 7b 的模型没有想到比之前又强大了非常多了。
手写单据
我们还是每次我都会测试的银行询证函的回函信息来做测试:

我用我的 macbook m3 max 128G 的本地跑 qwen2.5-vl-7b-instruct 模型:
我直接提问:“请帮我提取出回函结论中,“信息不符,请列明不符项目及具体内容”单元格内的手写的文字信息。”

我把它回答的信息单独列出来:
截止2022.12.31我司显示贵司的应收账款余额为:21926049.64 2022年1-12月累计含税销售额为:252637245.85
可以看到是完全准确的,之前使用2.0 版本的时候,7b 模型还不能完全把手写的数字搞准确。
现在这种手写的居然全对了。
要知道, 7b 的模型,在消费级显卡就可以跑起来!
同样场景下,那些手写的签收单什么的,不都可以自动提取了吗?
甚至直接提示词里让它给我们检查有没有对应签字或者盖章,
直接给我结果就好了。
特殊票据、凭证
对于被审计单位的细节测试,我们可能会去检查很多原始凭证。
以下面一张票据为例:

对于类似的票据,我们可能会让助理去登记一些信息。
但我们利用本地部署的AI可以直接识别出来,而且面对不同的票据,我们只需要更换提示词提取我们想要的字段:
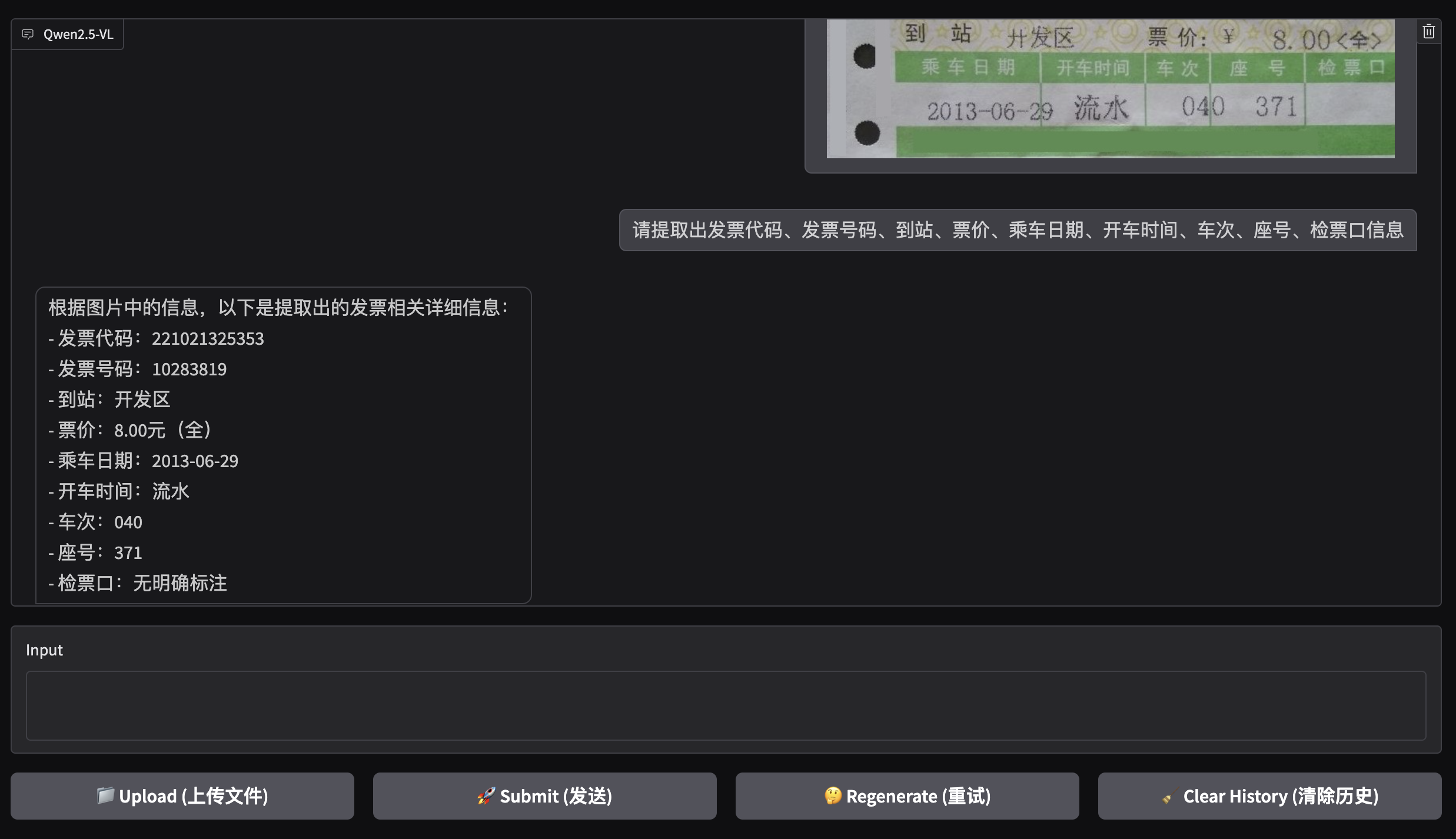
回答的信息如下:
根据图片中的信息,以下是提取出的发票相关详细信息:
- 发票代码:221021325353
- 发票号码:10283819
- 到站:开发区
- 票价:8.00元(全)
- 乘车日期:2013-06-29
- 开车时间:流水
- 车次:040
- 座号:371
- 检票口:无明确标注
很完美了。
我们甚至在审计场景中,可以让它直接帮我们检查是否有盖章以及盖章的公司名称:

很棒。
它甚至对于这样扭曲和有高光,人眼都不是很好识别的图片也能很好提取信息:

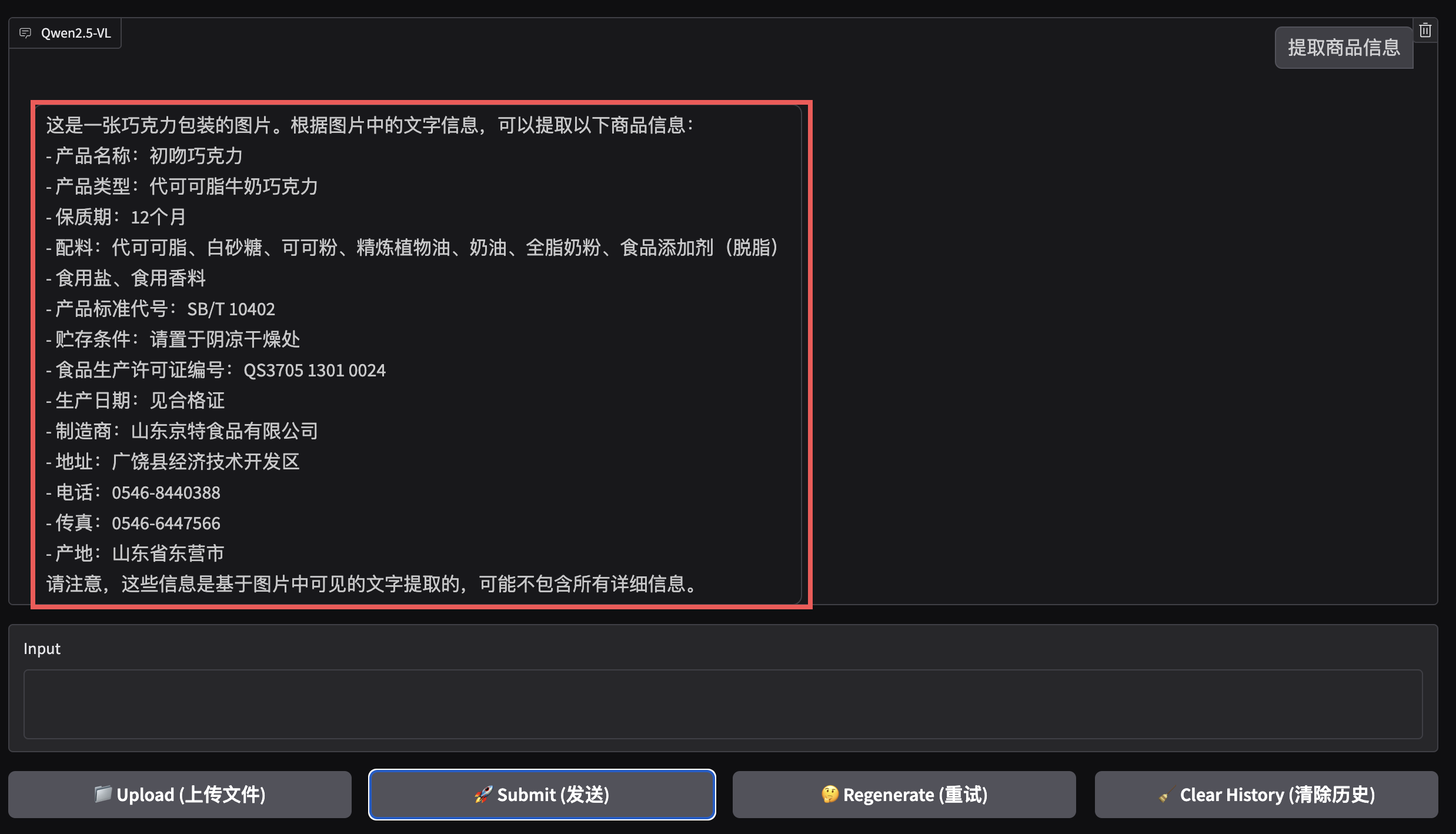
结束
平时大家关注的都是类似 DeepSeek 这样的大语言模型,
而视觉模型其实在审计场景中也值得关注。
审计过程中存在大量细节测试内容,
很多基础的检查工作依赖于助理肉眼去检查,
而这些工作有很大空间可以利用上视觉模型,
并且现在的开源模型已经非常强大,且所需成本非常低。
挖掘具体需求场景,嵌入到实际审计系统中已经完全可以实现,
相信有能力的事务所很快就可以运用起来。
参考网址
qwen2.5-VL 开源模型:https://github.com/QwenLM/Qwen2.5-VL/tree/main?tab=readme-ov-file
没有能力本地部署的朋友,可以使用通义千问的官网测试: