AI 提取合同关键信息
之前写过好几篇合同关键信息提取的方法,今天给大家介绍一个实现最简单,效率也不错的方法。
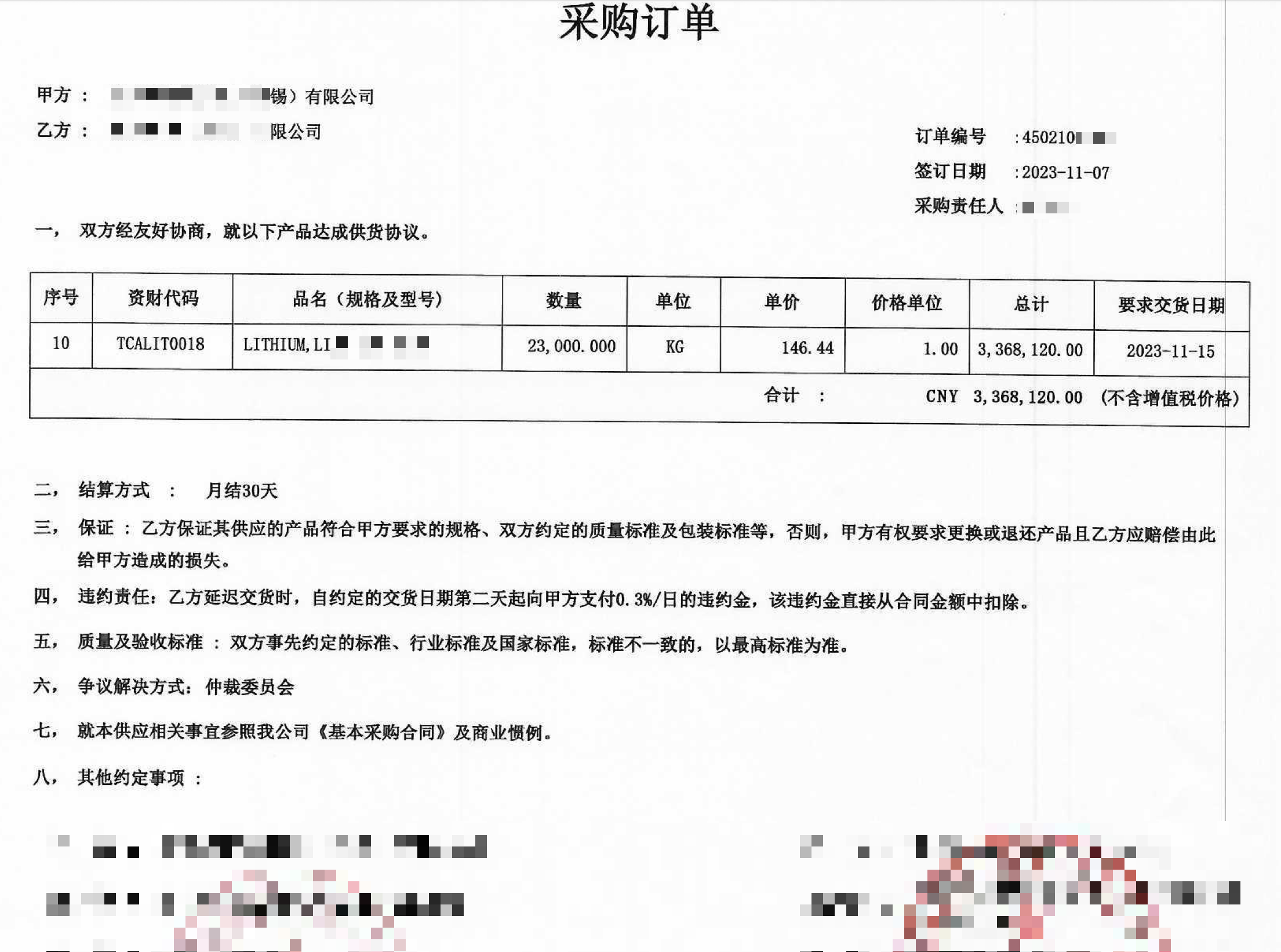
财审同事需要对被审计单位销售合同、采购合同、工程承包合同、工程分包合同的关键信息进行提取。
一般来说,他们会把这项工作交给效率工具-“实习生”来完成。
但是架不住量大,实习生用起来也不划算。
之前我们介绍过使用 paddlepaddle 和 knowledge-table 来实现。
其中 paddlepaddle 对于有 N 卡的效率高。
但我现在使用的 Mac 电脑,我发现使用 ollama 来实现是效率和部署最方便的。

前不久, ollama 提供了结构化输出的示例,要实现这个需求就更简单了。
对于扫描件的 PDF ,有两个方式可以实现:
- 直接使用 ollama 支持的视觉模型识别,并输出为结构化数据。
- 先将 PDF OCR 识别为 txt 文本文件,再使用 ollama 大模型识别出关键信息输出为结构化数据。
对于方式1来说,比较适用单据类,如发票、车票、报关单、凭证等。优势是效果好,缺点是速度慢。
对于方式2来说,比较适用几乎全是文本类的文书,如合同等。优势是速度快。
因此,本篇我们介绍方式2.
从 PDF OCR 识别为文本文件,有很多软件可以实现。不过,在 Mac 电脑上我直到今天才找到最好用的。
这里暂且不赘述。
假设我们已经将 PDF 转成了 txt 文件,我们只需要从文本中利用 AI 大模型提取出关键信息。
我们根据 ollama 官网给的示例,找 chatgpt 给我们写代码:
它直接给我可用代码:
from ollama import chat
from pydantic import BaseModel
from typing import Optional
# 定义一个模型来存储合同信息
class Contract(BaseModel):
contract_number: str # 销售合同或销售订单编号
sign_date: str # 合同签订日期
contract_term: str # 合同期限
contract_type: str # 合同类型
contract_subject: str # 合同标的
payment_method: str # 付款方式
settlement_basis: str # 结算依据
quantity_tons: float # 数量(吨)
unit_price_inclusive_tax: float # 单价(含税)
amount: float # 金额
transportation_party: str # 承担运输方
# 准备合同文本
contract_text = '''
销售合同编号: 12345
合同签订日期: 2024年10月15日
合同期限: 1年
合同类型: 销售合同
合同标的: 商品A
付款方式: 一次性支付
结算依据: 按照发票结算
数量(吨): 500
单价(含税): 1000
金额: 500000
承担运输方: 卖方承担运输
'''
# 调用 Ollama 模型进行处理,提取合同信息
response = chat(
messages=[
{
'role': 'user',
'content': f"请提取以下合同的关键信息:\n{contract_text}",
}
],
model='qwen2.5:7b-instruct',
format=Contract.model_json_schema(),
)
# 解析返回的 JSON 数据为 Contract 对象
contract_info = Contract.model_validate_json(response.message.content)
# 打印提取的合同信息
print(contract_info)其中 contract_text 是模拟的合同文本。
执行代码结果:
contract_number='12345' sign_date='2024年10月15日' contract_term='1年' contract_type='销售合同' contract_subject='商品A' payment_method='一次性支付' settlement_basis='按照发票结算' quantity_tons=500.0 unit_price_inclusive_tax=1000.0 amount=500000.0 transportation_party='卖方承担运输'当然,要将上面代码转变成可用的,只需要写个循环读取指定文件夹所有 txt 文件,批量调用函数,
同时,最后将信息输出为 excel 就可以了。
上面我使用的大模型是 qwen2.5:7b-instruct ,只需要占用 4.7 GB 的显存,对于显存稍微够一点的都可以跑起来。
当然,对于方式2 直接使用视觉模型对 PDF 的图片进行识别的话,可以使用 llama3.2-vision ,=minicpm-v= ,
其中 minicpm-v 专门针对中文的。
假如,梳理合同以前需要 4-5 个实习生,那么通过上述方法只需要 1 个了,仅仅是对生成的结果进行人工复核修正。