自动获取招标信息
所里每天通过邮件发招标信息。
但不同的审计团队还会关注一些指定客户的招标信息。
同事让帮忙自动获取下关注的网站的信息(主要是四川省的)。
所以这几天大概写了 40 多个爬虫,定时获取招标信息,并定时将含有指定关键词的信息发送邮件给同事。
scrapy 编写爬虫
scrapy 是个爬虫框架,相当于一个毛坯房,大部分功能是写好的,我要做的就是稍微精装修下。
针对每个网站,只需要浏览器中通过 F12 抓包获取信息,
模拟网页请求,获取数据。
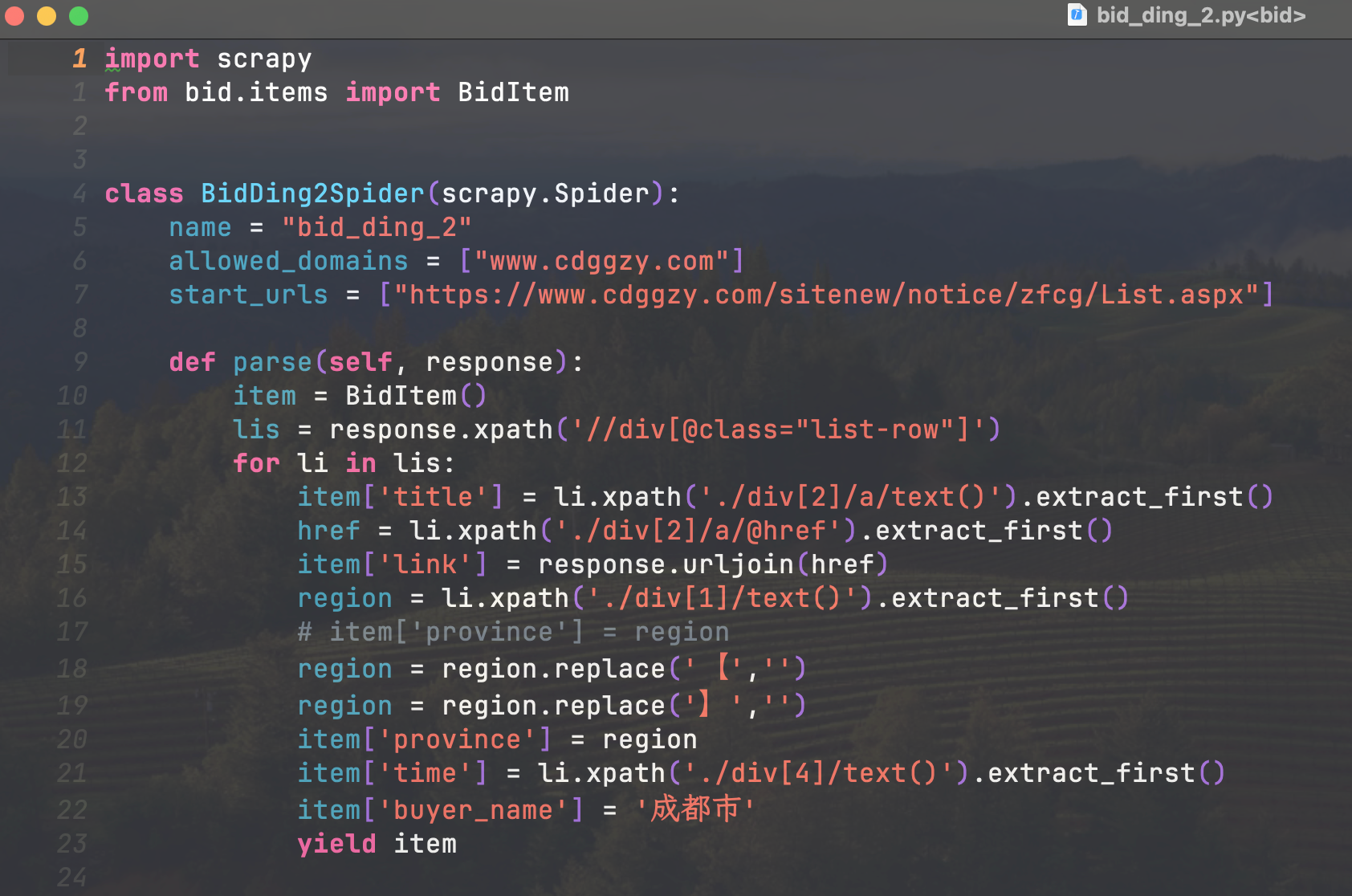
每个网页其实大概 10 几行代码,就可以写完。
一般 10 多分钟就可以搞定。
scrapyd + scrapyweb 可视化管理
Scrapyd 是一个用于运行分布式 scrapy 爬虫的调度器,可以对爬虫进行管理。
将项目直接部署在后台运行。
scrapyweb 是一个可视化管理工具,可以方便的设置定时任务:
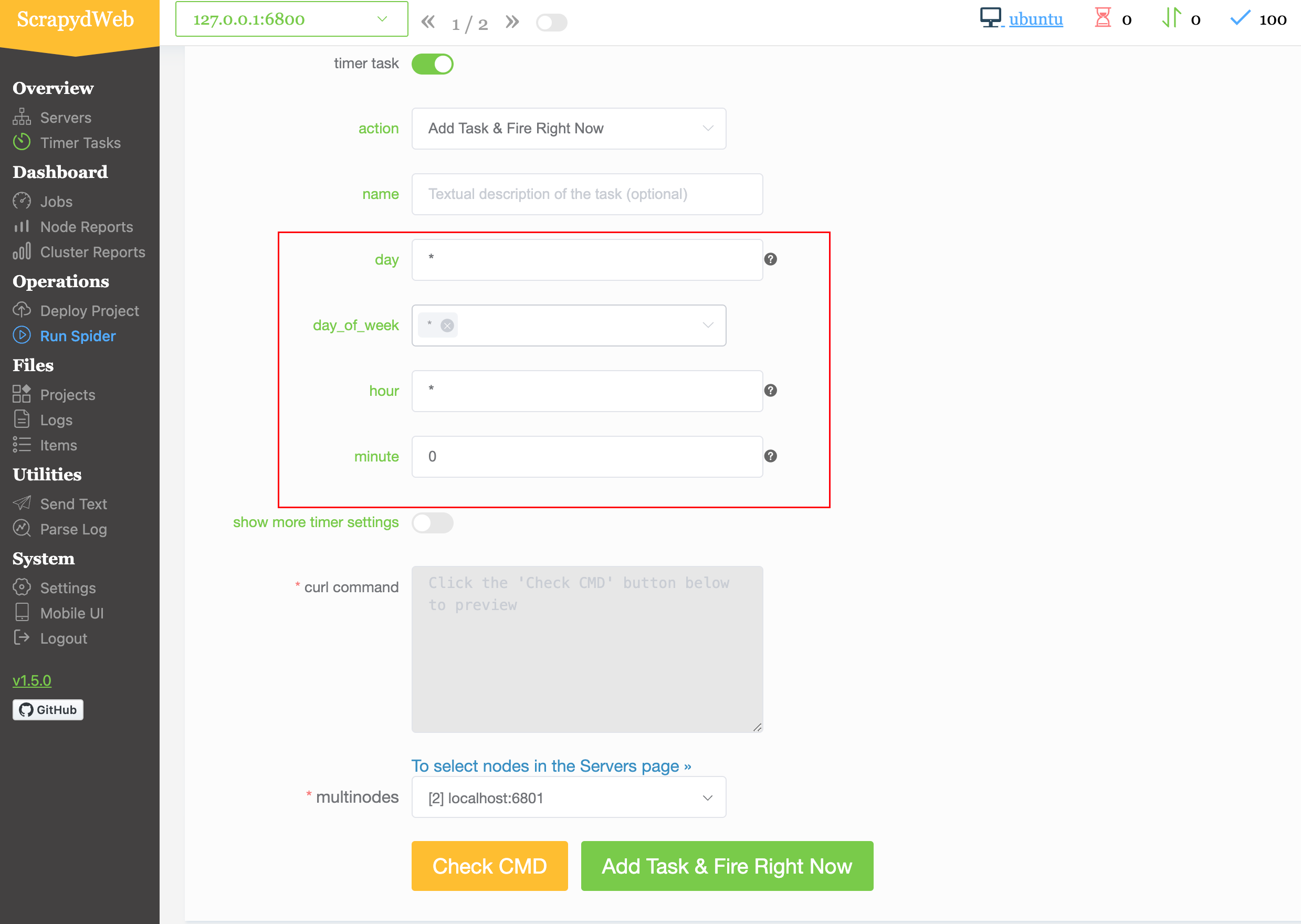
可以通过设置间隔多久执行一次任务,也可以设置几点几分执行一次任务。
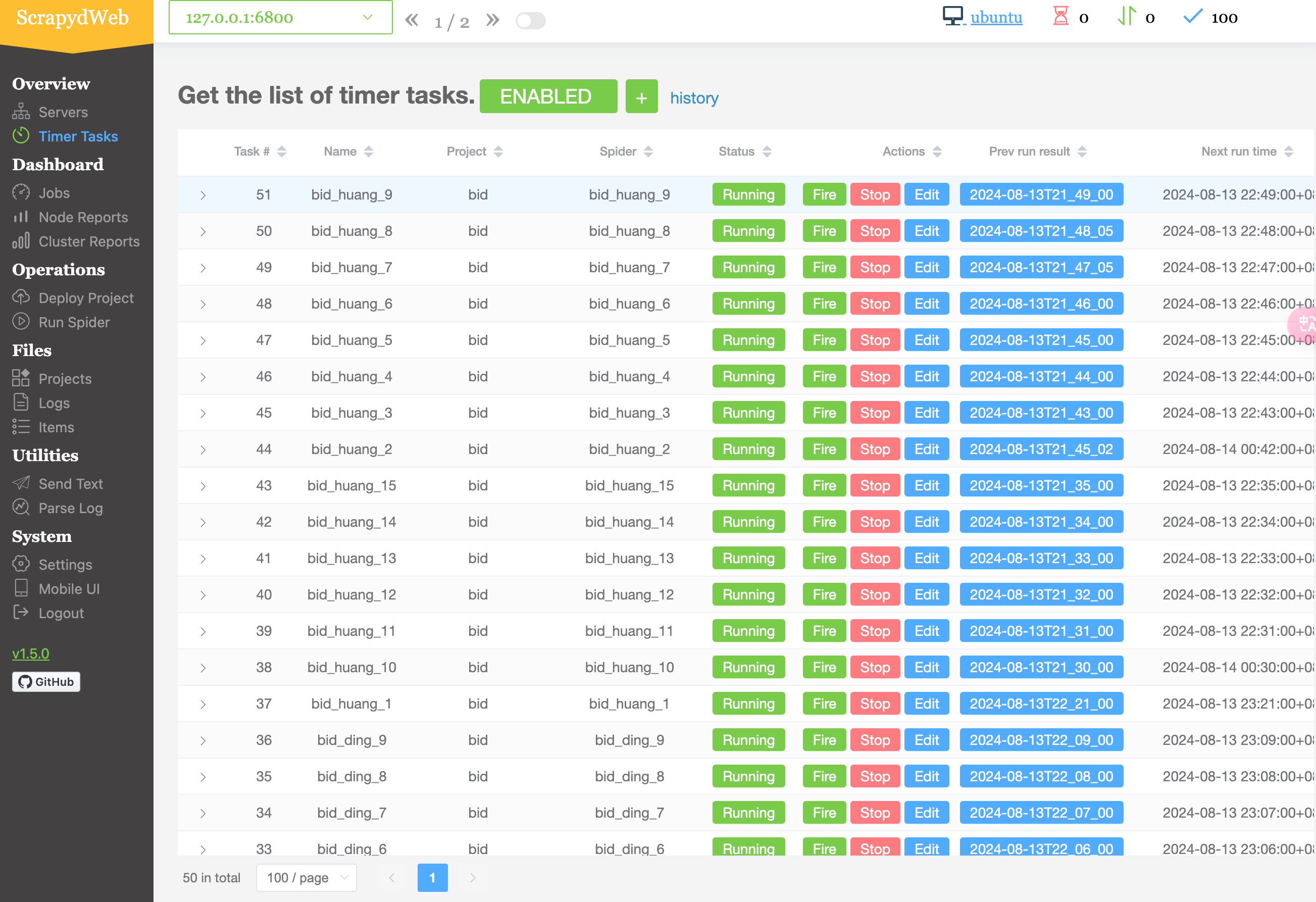
设置后,可以方便查看每个爬虫上一次执行的时间和下一次执行时间。
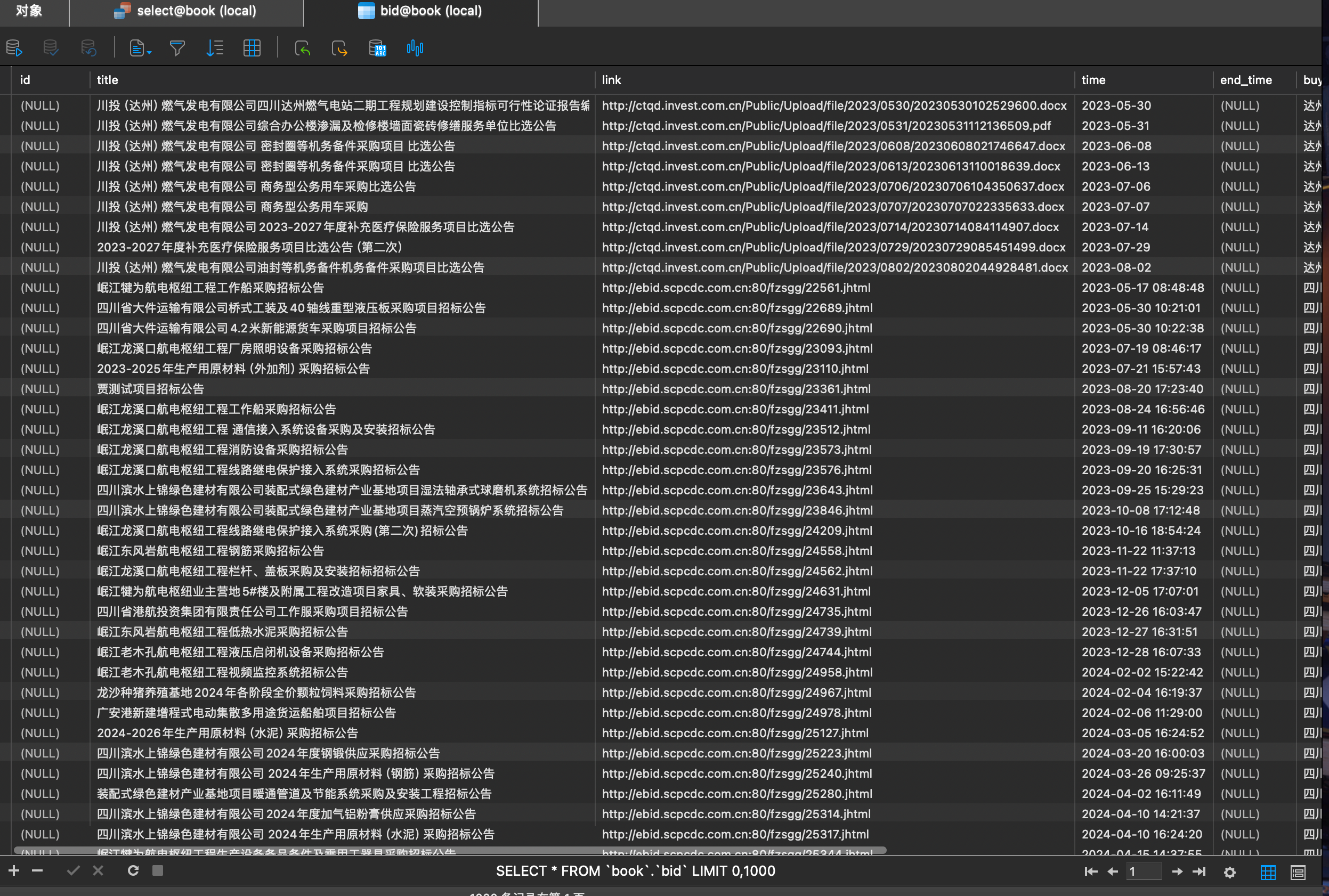
爬取的数据存储在数据库中,在获取数据的时候,我没有对关键词进行过滤,过滤的工作在发送邮件的时候进行。
自动发送邮件
对于审计团队,和IT审计团队维护不同筛选的关键词。
不同团队需要发送的邮件列表也维护在不同的 txt 文件中(方便后续添加发送人员)。
编写代码,每天下午4点半自动运行,
为每个团队查询数据库中的包含关键词的招标信息,并发送。
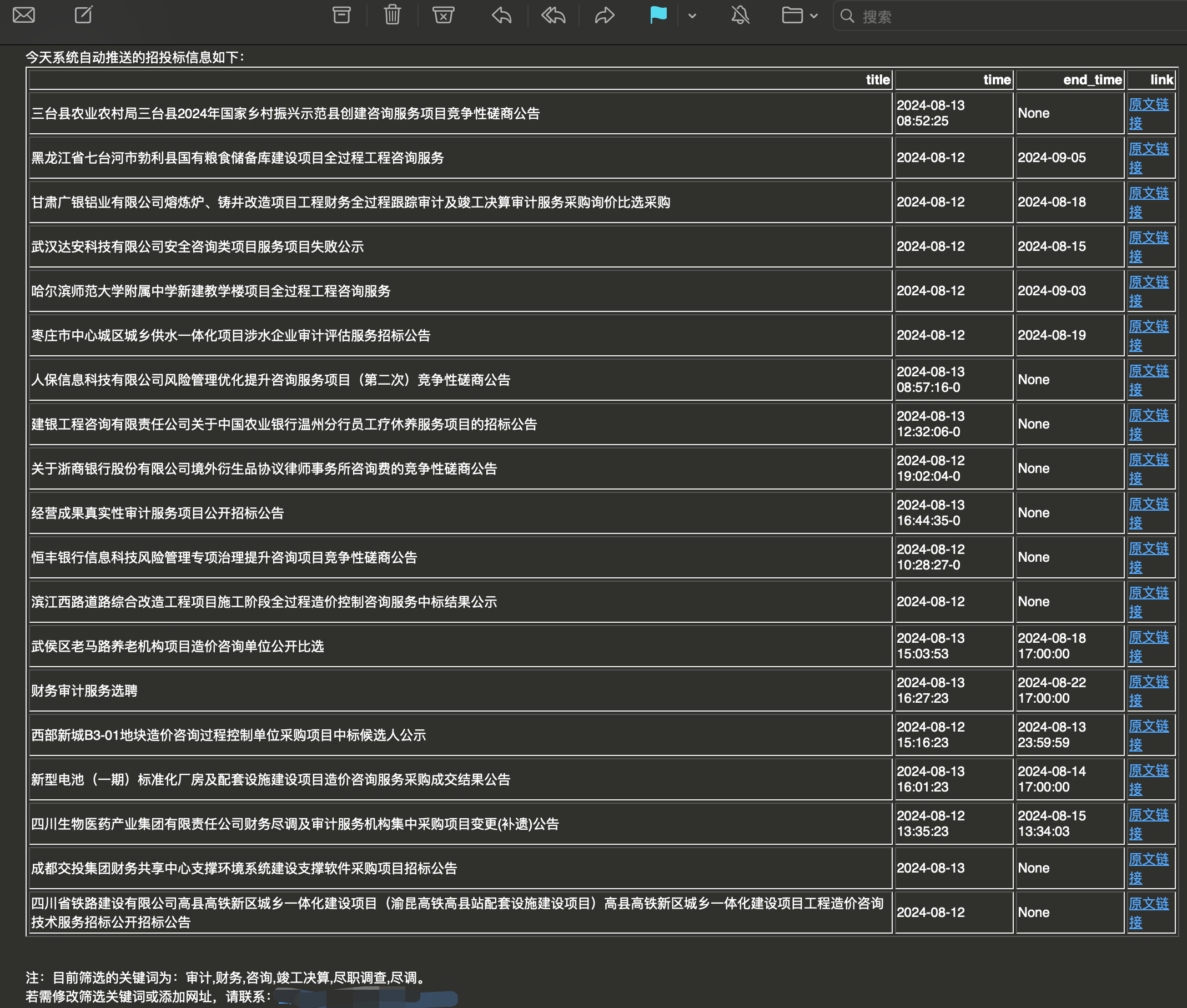
邮件中主要包含公告标题,开始、截止时间,以及原文链接。
发送财审同事邮件:
发送 IT 审计同事邮件:

为解决每天发送信息不能重复的问题,需要将发送的信息在数据库中进行标记,
标记过的信息,后面就不要再次发送。
同时为防止数据库的数据越来越多的问题,每天发送后自动删除一周前的信息。
结语
很久没有写爬虫了,花了 4 天时间搞了下。
开始有些忘记的知识学了学,稍微慢一点,
后面熟练了,基本差不多 10 分钟可以写一个。
有些不会写的,直接把抓包获取的请求信息给 chatgpt ,比较快速直接给我代码。
相比以前学的时候,还是简单太多了。
AI 还是好东西的。
假设对于这 40 多个网站,每天一个人花一个小时去整理。
那么,通过自动化,4 天时间,一劳永逸的解决,还是值得的。