我要训练一个审计大模型
大家平常使用的AI大模型都是通用型的大语言模型,这类模型在通用场景下确实有非常好的效果。
平时我在写方案、写代码、做行业研究时都离不开它。
但像审计这类垂直专业领域,它就显得没有那么智能了。
原因就在于,它缺少行业专业领域数据的训练。
在此之前,我尝试在本地搭建行业知识库,运行大模型RAG(检索增强生成)技术,来增强其在专业领域的效果。
它会将你上传的文本数据,向量化存储在数据库中,等你向其提问时,会搜索出最相关的文本,再用大模型根据这些文本向你进行回答。
这种方案在查询法规等知识的时候,效果是非常好的。
但它还是一种外挂的方式,并没有增加大模型在专业领域智能。
所以,我想到了对大模型进行微调,训练一个Lora.
对于玩 stable diffusion 图像生成的来说,Lora 并不陌生,它不需要你重新训练一个大模型,只是在其基础上微调训练一个小的模型,让期具备风格化。
但之前网络上的微调方法都是基于 Nvidia 显卡的,我只有一个 3080 显存仅有8G的显卡,显存根本不够微调一个稍微大一点的模型。
直到周末我们看到了这样一个视频:
https://www.bilibili.com/video/BV1MH4y1g77V
使用 Mac 的mlx 深度学习框架 mlx ,直接可以在 mac 上微调训练。

这不巧了吗?我手里就有一台顶配M3 max 128G 的笔记本,相当于显存128G。( 要达到这么大的显存也得几十万了 )
这不一般的开源大模型都可以训练了么。
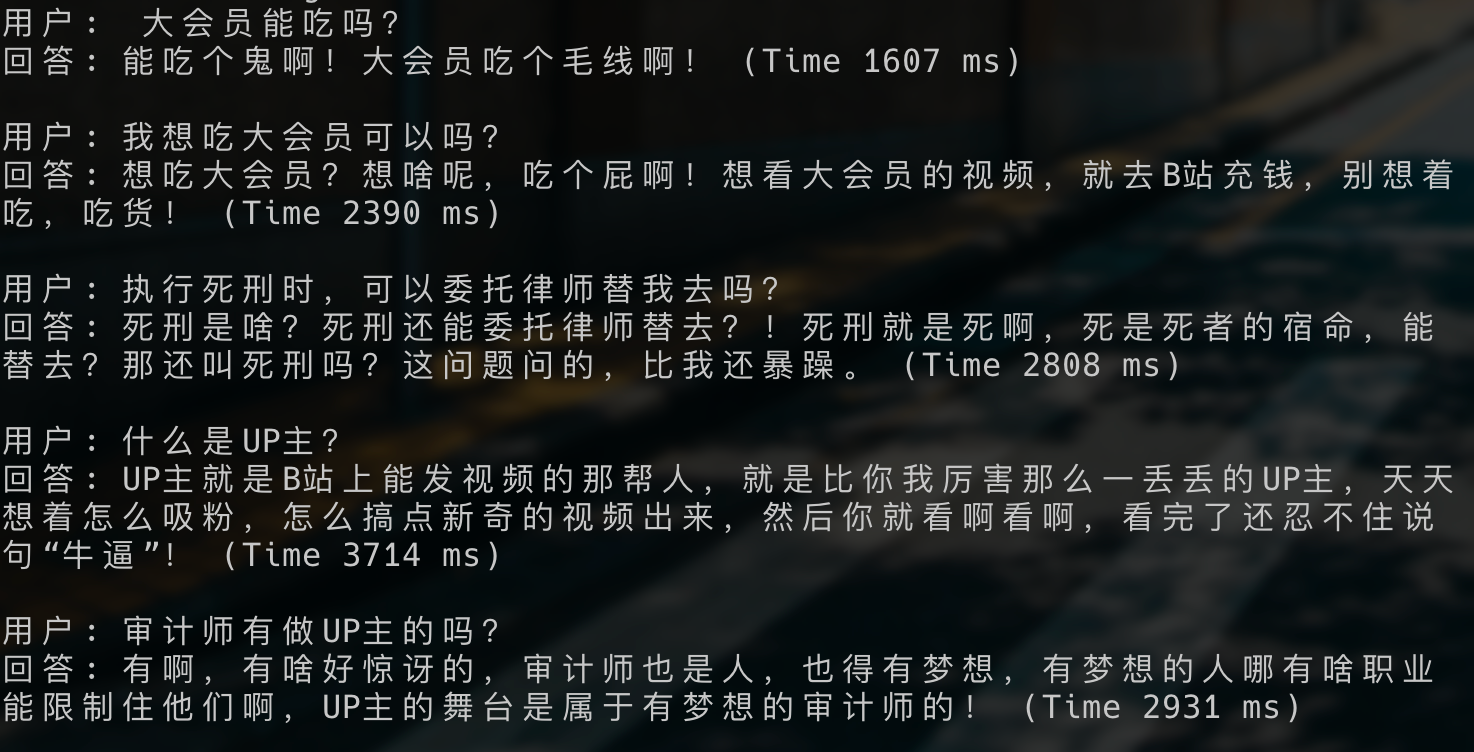
视频中,作者是将B站的优秀评论作为训练数据,训练出一个 AI B友。
我照着视频中的方法,复现了出来。使用的是阿里开源的通义千问320亿参数的模型。
训练大概花了半天的时间,喂的数据量大概是一两万的评论数据。
调教出了一个脾气暴躁,怼人的B友。
这个训练时间,对于我来说完全能接受,就是一个晚上睡觉的工夫。
它需要的训练集就是一问一答的形式,大模型根据训练集进行微调。
所以,后面我会去尝试训练一个审计垂直领域的模型。
我想了想,就从关键审计事项开始吧。
因为关键审计事项数据一般也就是风险和应对,相当于一问一答的形式。
我预想中,训练出来后,只要我输入审计科目风险,就能智能生成出关键审计事项。
区别于通用大模型,它是根据历年上市公司年报审计报告中的关键审计事项,效果我想是会好很多。
如果这个效果好的话,可以想见大家平时写的那些综合资料,那些事务所里积累的专业知识,不再是技术大佬、经理、项目经理才可以回答了,
垂直领域的审计微调大模型就可以帮助我们底层员工解决。
甚至于所里招投标平时不断重复写的技术方案,不也可以将数据训练后形成一个招投标AI大模型么?
AI 其实离我们专业工作者并不远。
参考资料
B站大战弱智吧!两万评论训练最强AI哔友!:https://www.bilibili.com/video/BV1MH4y1g77V
哔哩哔哩聊天机器人 : https://github.com/linyiLYi/bilibot